Это быстрый парсер с уклоном на универсальность, удобность и прозводительность.
На данный момент умеет парсить:
Поисковые системы
Google
Bing
Yahoo
Yandex
Каждый парсер может парсить ссылки, анкоры, сниппеты, количество страниц
Для гугла умеет обходить ограничение в 1000 результатов(скоро и для всех остальных парсеров так же будет), т.е. по одному запросу собирает всю выдачу
Парсеры кейвордов
Сервисы поиска ключевых слов
Yandex WordStat - собирает все кейворды и количество показов до указанной страницы. Так же собирает дополнительные кейворды, показы по главному кейворду и дату обновления статистики.
Подсказки поисковых систем
Подсказки и релейтед кеи Google
Подсказки и релейтед Bing
Подсказки, релейтед и трендовые кеи Yahoo
Подсказки и релейтед Yandex
Для подсказок гугла умеет автоматически собирать все кеи(подстановки до указанного уровня), для всех остальных парсеров такая возможность скоро так же появится
Параметры сайтов и доменов
Google PageRank - PR страниц и доменов
DMOZ - наличие сайта в каталоге DMOZ
Google TrustRank - проверка сайта на траст гугла(дополнительный блок ссылок в выдаче и т.п.)
Whois - дата экспайра домена
Планируется еще много парсеров в ближайшем будущем, все созданно для того чтобы быстро добавлять новые парсеры.
Не было бы никакого A-Parser'а если бы не он не имел все нижеперечисленные преимущества, оставляя остальные парсеры далеко в стороне:
Полностью интерактивный мега-юзабильный веб интерфейс
Быстрое добавление заданий - Quick Task, когда не нужны никакие настройки, а хочется только побыстрому спарсить результаты
Расширенный редактор заданий, позволяет комбинировать несколько парсеров в одном задании, к примеру можно одновременно парсить ссылки со всех парсеров поисковых систем, делать уник по всем результатам прямо в процессе работы и т.д.
Очередь заданий - статистика в реальном времени, выполнение одновременно нескольких заданий и т.д.
Встроенные подсказки для элементов управления позволяют просматривать хелп непосредственно в интерфейсе
Поддержка русского и английского языка
Огромная скорость работы
Поддержка двух самых популярных платформ - Linux и Windows, производительность под Windows фактически не отличается от Linux версии
Открытая разработка, багтрекер, выслушивание всех мнений и их реализация
Первоклассная тех поддержка, знакомая многим по моему старому проекту - A-Poster'у
Данный список можно еще долго продолжать, в ближайшее время все уникальные возможности и подробное их описание появится в Wiki
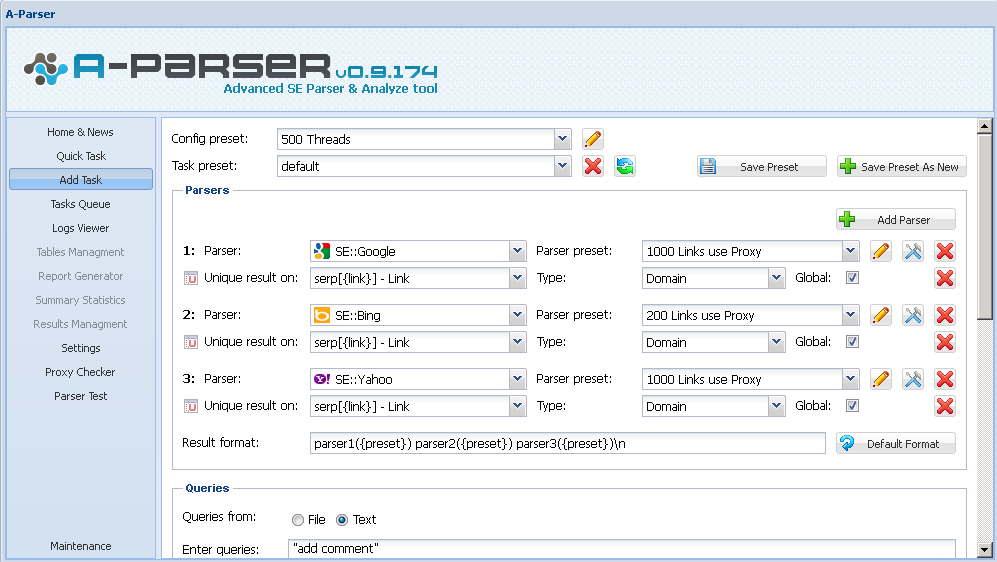
На данном скриншоте показан пример добавления задания на парсинг одновременно трёх поисковых систем - Google, Bing и Yahoo, одновременный уник по домену всех результатов
Ценовая политика
Цена лицензии - 200$, Абонентская плата - 15$ / 3 месяца, первые 3 месяца без абонентской платы.
Лицензия позволяет запускать A-Parser на одном сервере\компьютере. Переносить можно бесплатно, нельзя одновременно на нескольких запускать.
Чтобы купить - зарегистрируйтесь на a-parser.com и стучите в ICQ 777889
Предварительно перед покупкой с удовольствием отвечу на любые ваши вопросы, а так же возможно обсуждение реализации недостающего вам фукнционала.
32-й сборник рецептов, в котором подобраны 3 JS парсера для парсинга Yahoo Answers, оценки ключевых слов и сбора контактных данных фрилансеров.
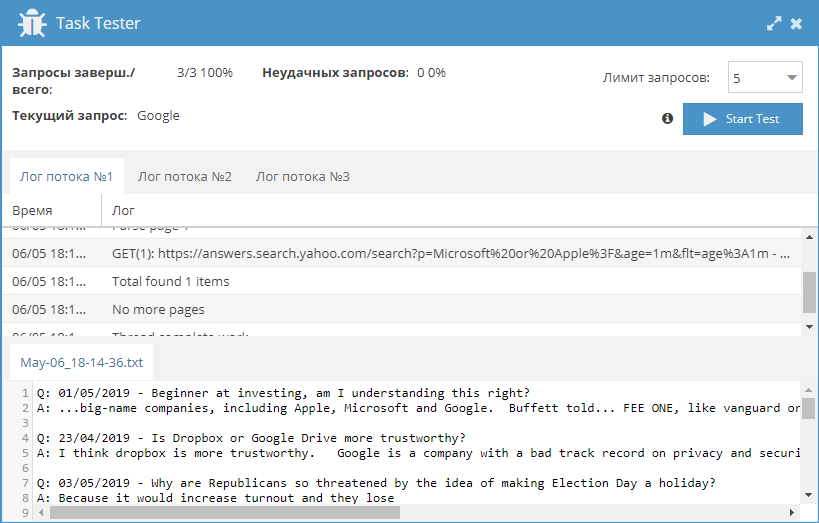
Парсер Yahoo Answers
Полноценный парсер сервиса Yahoo Answers, который по ключевым словам позволяет собирать непосредственно вопросы, ответы, а также их категории, дату создания и ссылки на страницы обсуждений.
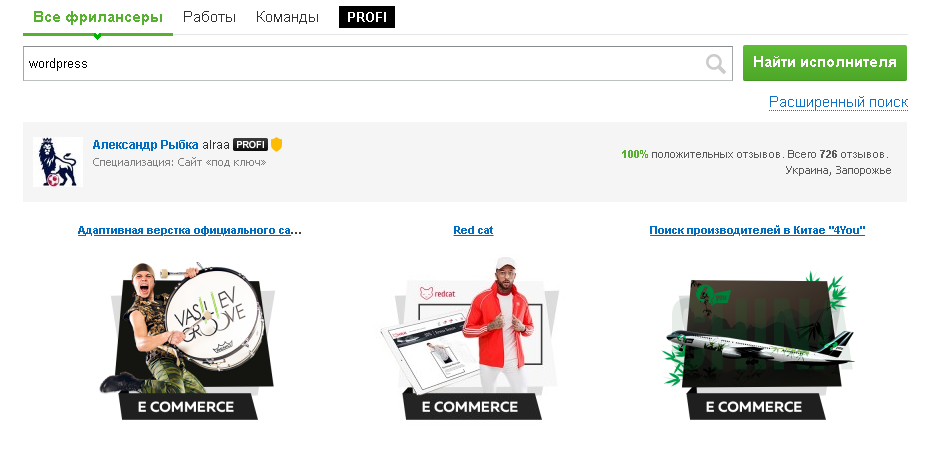
Парсинг контактов фрилансеров
Парсер, который ищет по ключевым словам фрилансеров и собирает их контакты. Данные собираются с сервиса fl.ru.
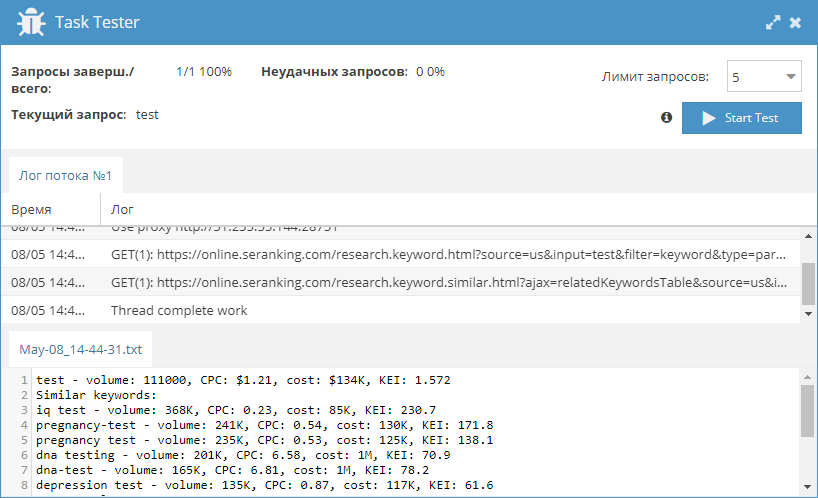
Анализ ключевых слов
Парсер для сервиса seranking.com. Кейворды оцениваются по 4-м показателям: частотность, стоимость клика (CPC), стоимость трафика и KEI. Также есть возможность собирать похожие, релевантные и подсказки к начальному запросу вместе с их показателями.
Еще больше различных рецептов в нашем Каталоге!
Предлагайте ваши идеи для новых парсеров здесь, лучшие будут реализованы и опубликованы.
Подписывайтесь на наш канал на Youtube - там регулярно выкладываются видео с примерами использования A-Parser, а также следите за новостями в Twitter.
JS парсеры: для this.request добавлена опция data_as_buffer, которая определяет возвращать data как строку(String) или объект Buffer
Исправления в связи с изменениями в выдаче
В
SE::Google::Modern исправлена работа с рекаптчами, исправлен парсинг сниппетов, а также исправлен парсинг мобильной выдачи
Rank::SEMrush полностью переписан, также полностью изменился список собираемых данных, парсер возвращает только те данные, которые доступны без авторизации
Сбор всех организаций в определенной местности
Начиная с версии 1.2.482 в A-Parser появились парсеры карт Google и Яндекс. Принцип работы обоих одинаков - в настройках указываются координаты точки и зум, парсер собирает результаты поиска по ключевым словам в этой точке и области вокруг нее, ограниченной зумом. Но если стоит задача собрать данные, например, со всего города, то для ее решения нужно указывать диапазон координат и "заставить" парсер пройтись по ним. Как это сделать, а также пример пресета - все это показано по ссылке выше.
Парсер собирающий вопросы и ответы из выдачи Google
Google по некоторым запросам показывает в поисковой выдаче блок вопросов и ответов People also ask (Похожие запросы). Наши пользователи периодически интересуются, как можно парсить этот блок, получая отдельно вопросы и ответы на них. Поэтому мы публикуем в нашем каталоге пример такого парсера, а забрать его можно по ссылке выше.
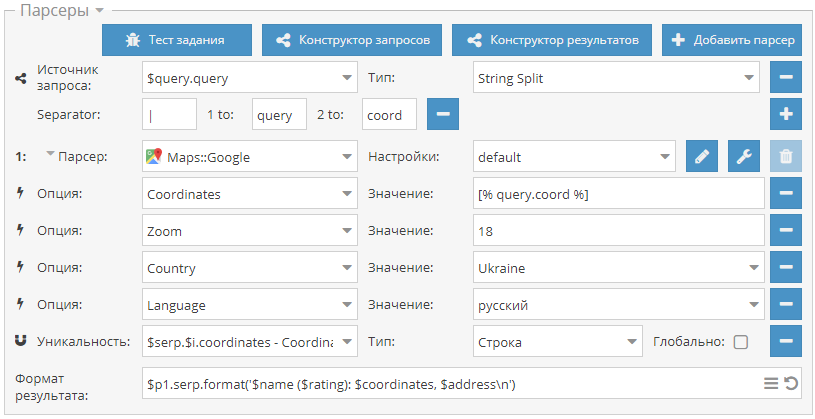
Использование файлов целиком в качестве запросов
Общеизвестно, что в А-Парсере каждая строка в исходном файле - это отдельный запрос. Но существуют задачи, когда необходимо использовать все содержимое файла как один запрос, игнорируя разбивку на строки. Благодаря JavaScript парсерам такая возможность есть и по ссылке выше опубликован пример парсера, который получает все содержимое файла, переводит его на заданный язык и сохраняет в новый файл.
Еще больше различных рецептов в нашем Каталоге!
Предлагайте ваши идеи для новых парсеров здесь, лучшие будут реализованы и опубликованы.
Подписывайтесь на наш канал на Youtube - там регулярно выкладываются видео с примерами использования A-Parser, а также следите за новостями в Twitter.
Видео урок: Макросы подстановок
В этом видеоуроке мы изучим один из инструментов для работы с запросами - макросы подстановок. С их помощью можно значительно увеличивать количество запросов, листать страницы и многое другое.
В уроке рассмотрено:
макрос {num} на примерах прохода по страницам и перебора координат в парсере Google maps
макрос {az} на примере парсинга по доркам для увеличения кол-ва запросов и соответственно результатов
макрос {each} на примере парсинга подсказок для генерации словосочетаний
Полезные ссылки:
https://a-parser.com/wiki/query-format/#Макросы-подстановок - документация по макросам подстановок
https://a-parser.com/resources/336/ - пресет по перебору координат в
Maps::Google
https://a-parser.com/resources/340/
https://a-parser.com/resources/341/ - пресет для парсинга по доркам
https://a-parser.com/resources/342/ - пресет для парсинга подсказок
[URL=1.2.534 - 6 новых парсеров, поддержка Node.js в tools.js, множество исправлений в парсерах]1.2.534 - 6 новых парсеров, поддержка Node.js в tools.js, множество исправлений в парсерах[/URL]
Улучшения
Добавлено 4 новых парсера Instagram
Social::Instagram::Post - парсинг данных о постах, в т.ч. комментарии и пользователей, которые лайкнули пост
Добавлена поддержка дробных чисел в макросе подстановок {num}
Добавлена поддержка Node.js в tools.js, теперь можно использовать возможности Node.js (включая модули) в обычных пресетах во всех полях кроме Parse custom results, фильтров и Конструкторов результатов
Шаблоны Template Toolkit в настройках парсеров теперь работают для всех запросов
Стабилизирована работа
SE::Google::Modern после изменений со стороны Google, благодаря чему несколько уменьшилось количество рекаптч
Улучшена проверка ответа в
Maps::Yandex, улучшен сбор картинок, а также добавлена возможность собирать ссылки на страницу организации
API: для oneRequest/bulkRequest добавлен параметр needData, указывающий, передавать ли в ответе data/pages, используется для экономии памяти, по умолчанию отключен
Обновлены apps.json и user-agents.txt, при установке обновления также рекомендуется обновить эти файлы
Исправления в связи с изменениями в выдаче
Исправлена ситуация, при которой в
SE::Google::Modern выдавался 597 код ответа
В
SE::Yandex исправлена ситуация, при которой в результатах появлялись "пустые" ссылки, а также исправлен парсинг сниппетов в мобильной выдаче
Исправлена редко встречающаяся проблема с
SE::Google::Translate, когда парсер получал в ответ 403 статус
Сбор ссылок с GET параметрами
В техническую поддержку часто задают вопрос, как собирать ссылки с GET параметрами для поиска SQL уязвимостей. Поэтому, по ссылке выше мы расскажем как это сделать, используя стандартный парсер Google.
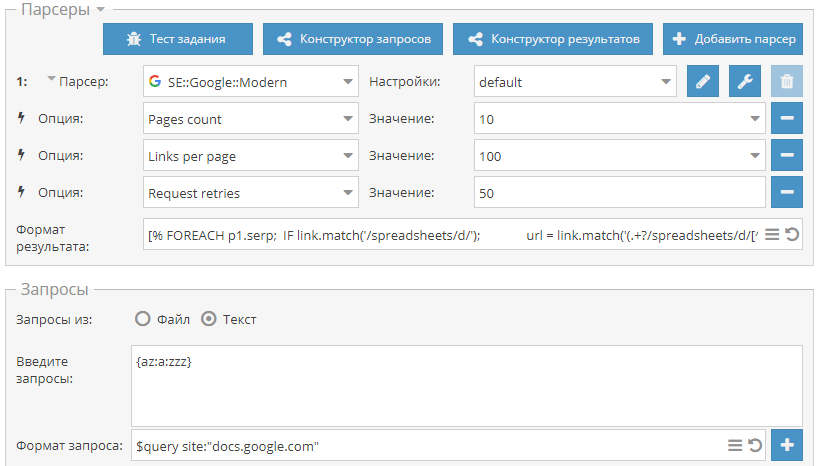
Поиск и скачивание Google документов
За последнее время уже несколько раз появлялись новости о том, что Google индексирует пользовательские документы, размещенные в их одноименном сервисе и открытые для доступа по ссылке. Соответственно все эти файлы становятся доступны в поиске. И пока Google разбирается с этим, по ссылке выше мы рассказываем как можно искать и скачивать такие документы.
Работаем с API, часть 3
Третья и заключительная часть из цикла статей по работе с A-Parser через API. В ней на примере очистки очереди задач будет рассмотрена работа со вспомогательными запросами, которые позволяют работать с очередью заданий. Все детали - по ссылке выше.
Если вы хотите, чтобы мы более подробно раскрыли какой-то функционал парсера, у вас есть идеи для новых статей или вы желаете поделиться собственным опытом использования A-Parser (за небольшие плюшки ) - отписывайтесь здесь.
Подписывайтесь на наш канал на Youtube - там регулярно выкладываются видео с примерами использования A-Parser, а также следите за новостями в Twitter.
34-й сборник рецептов, в котором опубликован пресет для оценки количества трафика на сайтах, парсер Ahrefs через API и пресет для парсинга информации об IP адресах. Поехали!
Чек трафика сайта
Пресет для проверка трафика сайта через сервис siteworthtraffic.com. Собираются данные о количестве уникальных постетителей и просмотров, а также о доходе с рекламы. Оценка трафика на сайтах может быть полезна для фильтрации списка сайтов по критерию прибыльности и популярности. Пресет доступен по ссылке выше.
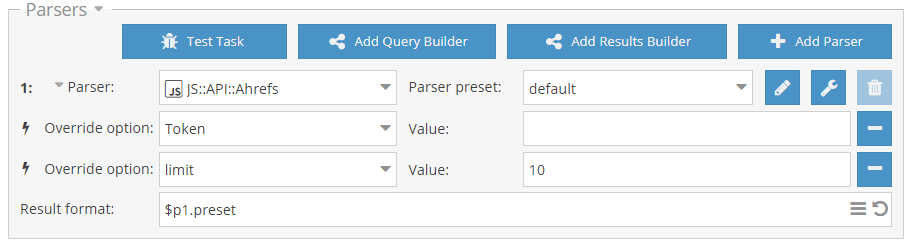
Парсер Ahrefs на основе Ahrefs API
Парсер для сбора данных из популярного сервиса Ahrefs через их официальное API. Собирается множество данных, которые позволяют оценивать домены по различным характеристикам. Для использования нужен API ключ, который приобретается отдельно.
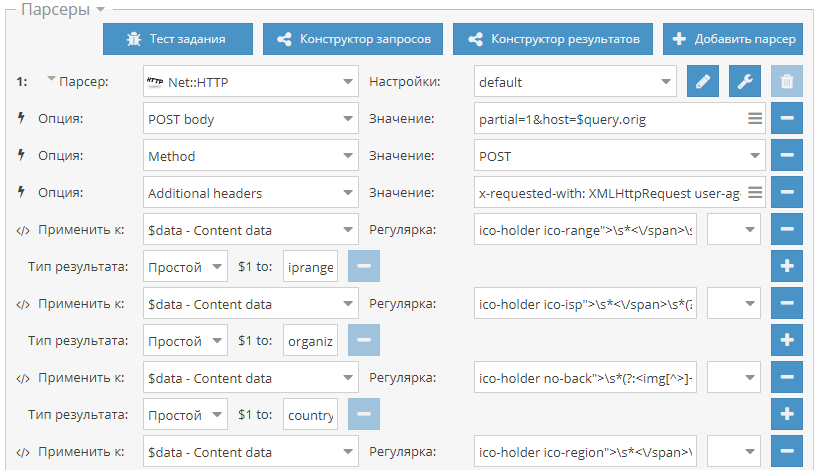
Парсинг подсети и организации по IP
Небольшой пресет для сбора информации об IP адресе, а именно: подсеть, организация, страна и город. Данные собираются из сервиса whoer.net.
Еще больше различных рецептов в нашем Каталоге!
Предлагайте ваши идеи для новых парсеров здесь, лучшие будут реализованы и опубликованы.
Подписывайтесь на наш канал на Youtube - там регулярно выкладываются видео с примерами использования A-Parser, а также следите за новостями в Twitter.
Видео урок: Поиск страниц контактов
В этом видео уроке рассмотрен пример решения задачи по поиску страниц контактов у заданного списка сайтов. Также парсится тайтл и все это сохраняется в CSV файл.
В уроке рассмотрено:
парсинг поиска Google для получения ссылки на страницу контактов
парсинг главной страницы сайта для получения title
использование инструмента $tools.CSVline для форматирования файла результата
Сборник рецептов #35: комментарии на Youtube, контакты на сайтах и японский Yahoo
35-й сборник результатов, где мы будем собирать комментарии из Youtube, искать контакты (телефоны и почты) на сайтах, а также парсить японскую выдачу Yahoo. Поехали!
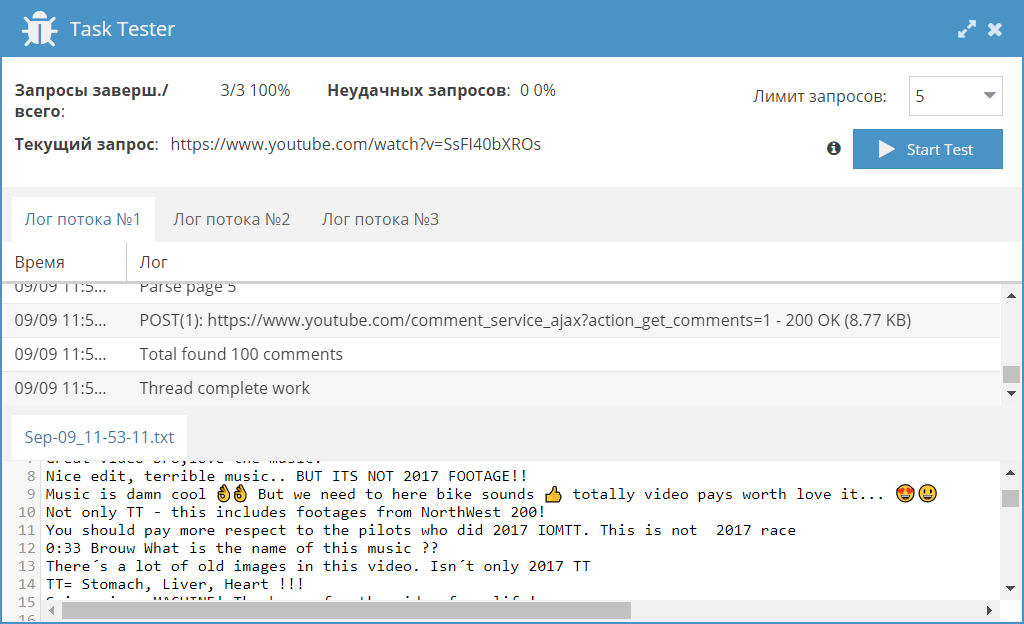
Парсинг комментариев из Youtube
Представляем вашему вниманию JS парсер комментариев для видео на Youtube. С его помощью можно собирать тексты комментариев, а также информацию об авторах комментариев индивидуально для каждого видео. Также реализована возможность указывать количество страниц с комментарими, что позволяет при необходимости ограничить их сбор и тем самым увеличить скорость работы.
Извлекаем телефоны, начинающиеся на 3 с помощью HTML::EmailExtractor
Пресет, в котором показано, как с помощью HTML::EmailExtractor HTML::EmailExtractor собирать контакты со страниц сайтов. Данный пресет предназначен для сбора e-mail и телефонов, начинающихся с 3 (Украина), но при необходимости можно немного изменить регулярные выражения и собирать телефоны других стран.
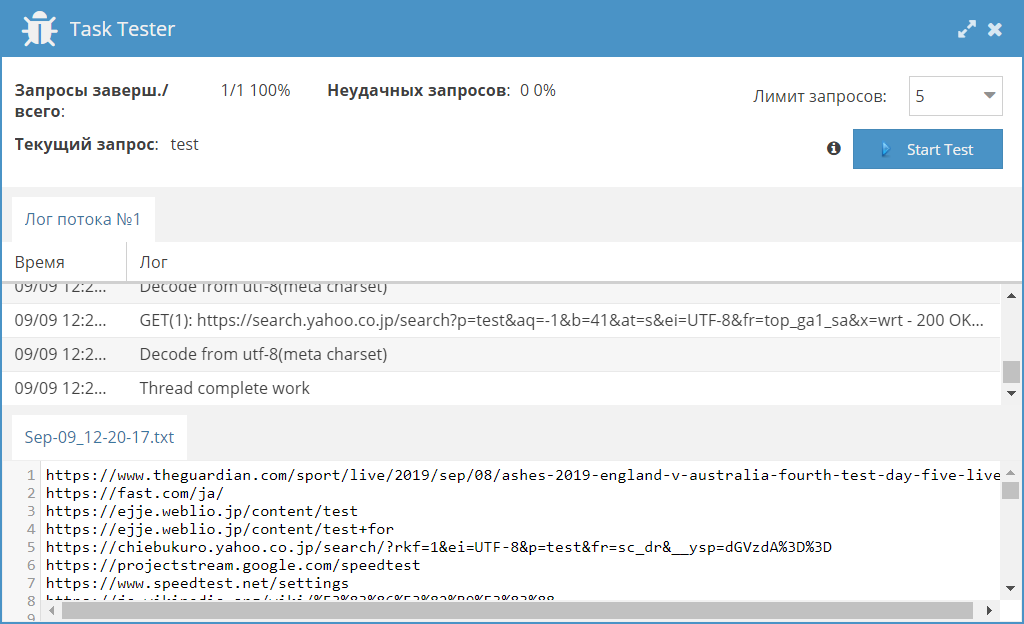
SE::Yahoo::JP
JS парсер для парсинга японской выдачи Yahoo. Используется домен search.yahoo.co.jp. Собираются ссылки, анкоры и сниппеты, а также есть возможность задать количество страниц для парсинга.
Добавлен инструмент $tools.CSVline для простого создания CSV файлов
В связи с тестированием Гуглом новой верстки в поисковике, добавлена ее поддержка в
SE::Google::Modern
В
SE::Google::Modern в массив $serp добавлена переменная $amp, которая показывает, поддерживает ли страница AMP
В
SE::Yandex в $serp.$i.label добавлена поддержка Турбо страниц, а также добавлен сбор типов меток сайтов
В
Net::HTTP улучшена работа с редиректами, добавлена опция Follow common redirects
Теперь в
Util::ReCaptcha2 можно указать хост для используемого сервиса разгадывания, а также в Provider url можно указывать адреса через запятую (актуально для XEvil и CapMonster), парсер будет использовать каждый из них в случайном порядке
В этом видео уроке рассмотрен способ сбора данных об организациях в указанной местности из Google Maps, используя встроенный парсер Гугл карт. Также показано как определить необходимые координаты на карте и задать их в парсере.
В уроке рассмотрено:
Парсинг карт Google с использованием Maps::Google
Пример получения координат для использования в макросах подстановок
Работа с макросами подстановок при наличии отрицательных чисел
9-й сборник статей. В нем мы разберемся, как делать пресеты для анализа всех страниц сайта, научимся парсить все ссылки сайта из индекса ПС и будем проверять существование запросов. Поехали!
Создание пресета для анализа страниц сайта
Анализ страниц на сайте - это один из самых популярных кейсов использования А-Парсера. При этом можно собирать очень много различных параметров, начиная от проверки доступности и заканчивая поиском определенных слов на странице.
О том, как сделать простой анализатор сайта и пойдет речь в этой статье.
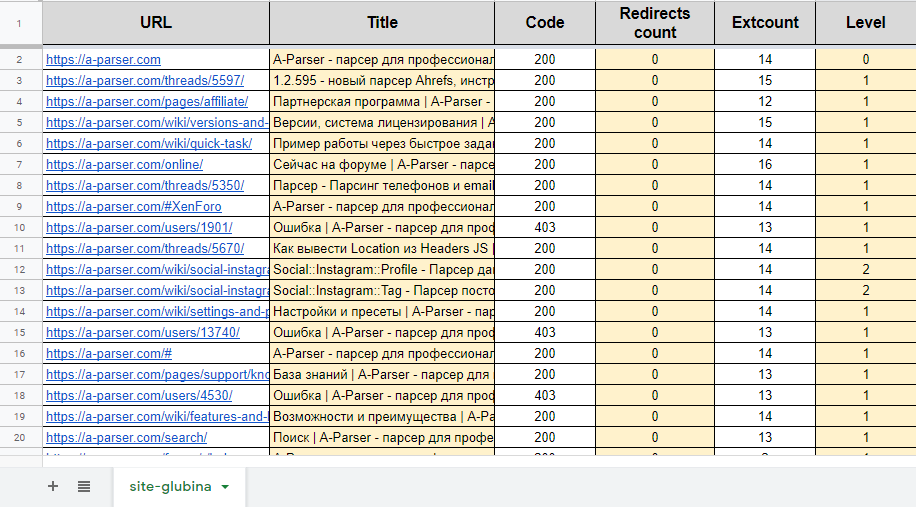
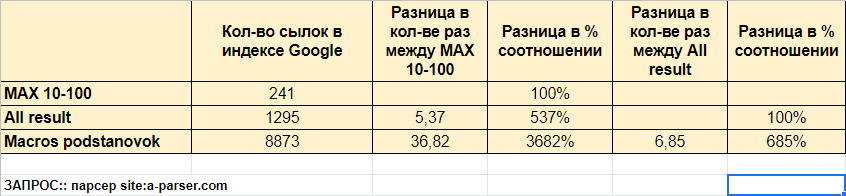
Парсинг разными способами максимум результатов из индекса поисковых систем
Парсинг из индекса поисковых систем всех страниц сайта - это еще один популярный кейс для A-Parser. ПС ограничивают кол-во результатов по одному запросу, поэтому нужно как-то обходить это ограничение. Как это сделать - описано в нашей статье.
Проверка существования запросов
Пресет из этого примера позволяет проверить базу ключевых слов и определить, был ли запрос одноразовым без постоянного спроса или нет. Тем самым появляется возможность отфильтровать семантику и оставить только "хорошие" запросы. Больше деталей, а также готовый пресет - по ссылке выше.
Если вы хотите, чтобы мы более подробно раскрыли какой-то функционал парсера, у вас есть идеи для новых статей или вы желаете поделиться собственным опытом использования A-Parser (за небольшие плюшки ) - отписывайтесь здесь.
Подписывайтесь на наш канал на Youtube - там регулярно выкладываются видео с примерами использования A-Parser, а также следите за новостями в Twitter.
Вы не можете начинать темы Вы не можете отвечать на сообщения Вы не можете редактировать свои сообщения Вы не можете удалять свои сообщения Вы не можете голосовать в опросах





 Google
Google
 Bing
Bing
 Yahoo
Yahoo
 Yandex
Yandex
 Yandex WordStat - собирает все кейворды и количество показов до указанной страницы. Так же собирает дополнительные кейворды, показы по главному кейворду и дату обновления статистики.
Yandex WordStat - собирает все кейворды и количество показов до указанной страницы. Так же собирает дополнительные кейворды, показы по главному кейворду и дату обновления статистики.

 Google PageRank - PR страниц и доменов
Google PageRank - PR страниц и доменов
 DMOZ - наличие сайта в каталоге DMOZ
DMOZ - наличие сайта в каталоге DMOZ
 Google TrustRank - проверка сайта на траст гугла(дополнительный блок ссылок в выдаче и т.п.)
Google TrustRank - проверка сайта на траст гугла(дополнительный блок ссылок в выдаче и т.п.)
 Whois - дата экспайра домена
Whois - дата экспайра домена




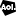




















 ) - отписывайтесь
) - отписывайтесь 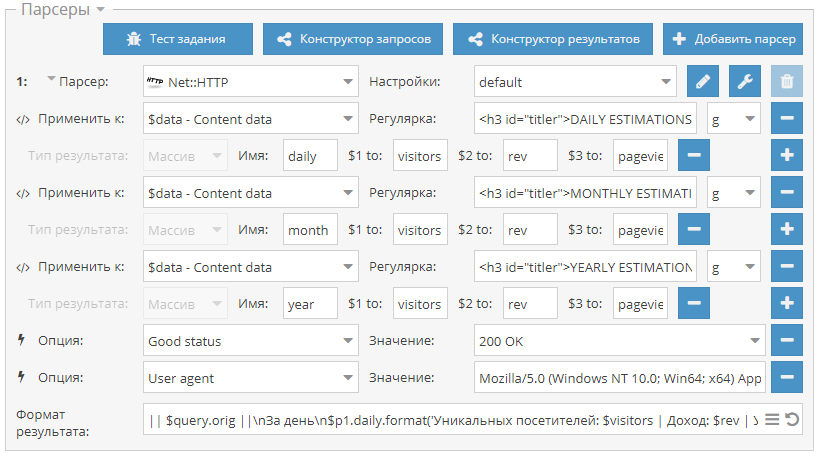




 Net::HTTP
Net::HTTP Util::ReCaptcha2
Util::ReCaptcha2 SE::Rambler
SE::Rambler Social::Instagram::Profile
Social::Instagram::Profile Social::Instagram::Tag
Social::Instagram::Tag