|
На страницу 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11 ... 14, 15, 16, 17, 18, 19, 20, 21, 22, 23 След. |
|
|
![]()
Forbidden
Свой |
Зарегистрирован: 18.02.2009
Сообщений: 66
|
Обратиться по нику
|
| Forbidden |
Ответить с цитатой | | |
|
Что такое A-Parser?
Это быстрый парсер с уклоном на универсальность, удобность и прозводительность.
На данный момент умеет парсить:
Поисковые системы
Каждый парсер может парсить ссылки, анкоры, сниппеты, количество страниц
Для гугла умеет обходить ограничение в 1000 результатов(скоро и для всех остальных парсеров так же будет), т.е. по одному запросу собирает всю выдачу
Парсеры кейвордов
Сервисы поиска ключевых слов
-
 Yandex WordStat - собирает все кейворды и количество показов до указанной страницы. Так же собирает дополнительные кейворды, показы по главному кейворду и дату обновления статистики.
Yandex WordStat - собирает все кейворды и количество показов до указанной страницы. Так же собирает дополнительные кейворды, показы по главному кейворду и дату обновления статистики.
Подсказки поисковых систем
-

 Подсказки и релейтед кеи Google
Подсказки и релейтед кеи Google
-
 Подсказки и релейтед Bing
Подсказки и релейтед Bing
-
 Подсказки, релейтед и трендовые кеи Yahoo
Подсказки, релейтед и трендовые кеи Yahoo
-
 Подсказки и релейтед Yandex
Подсказки и релейтед Yandex
Для подсказок гугла умеет автоматически собирать все кеи(подстановки до указанного уровня), для всех остальных парсеров такая возможность скоро так же появится
Параметры сайтов и доменов
-
 Google PageRank - PR страниц и доменов
Google PageRank - PR страниц и доменов
-
 DMOZ - наличие сайта в каталоге DMOZ
DMOZ - наличие сайта в каталоге DMOZ
-
 Google TrustRank - проверка сайта на траст гугла(дополнительный блок ссылок в выдаче и т.п.)
Google TrustRank - проверка сайта на траст гугла(дополнительный блок ссылок в выдаче и т.п.)
-
 Whois - дата экспайра домена
Whois - дата экспайра домена
Планируется еще много парсеров в ближайшем будущем, все созданно для того чтобы быстро добавлять новые парсеры.
Не было бы никакого A-Parser'а если бы не он не имел все нижеперечисленные преимущества, оставляя остальные парсеры далеко в стороне:
- Полностью интерактивный мега-юзабильный веб интерфейс
- Быстрое добавление заданий - Quick Task, когда не нужны никакие настройки, а хочется только побыстрому спарсить результаты
- Расширенный редактор заданий, позволяет комбинировать несколько парсеров в одном задании, к примеру можно одновременно парсить ссылки со всех парсеров поисковых систем, делать уник по всем результатам прямо в процессе работы и т.д.
- Очередь заданий - статистика в реальном времени, выполнение одновременно нескольких заданий и т.д.
- Встроенные подсказки для элементов управления позволяют просматривать хелп непосредственно в интерфейсе
- Поддержка русского и английского языка
- Огромная скорость работы
- Поддержка двух самых популярных платформ - Linux и Windows, производительность под Windows фактически не отличается от Linux версии
- Открытая разработка, багтрекер, выслушивание всех мнений и их реализация
- Первоклассная тех поддержка, знакомая многим по моему старому проекту - A-Poster'у
- Данный список можно еще долго продолжать, в ближайшее время все уникальные возможности и подробное их описание появится в Wiki
Более подробное описание и скриншоты
Wiki - дополнительная информация, инструкции и т.д.
Скриншот интерфейса:
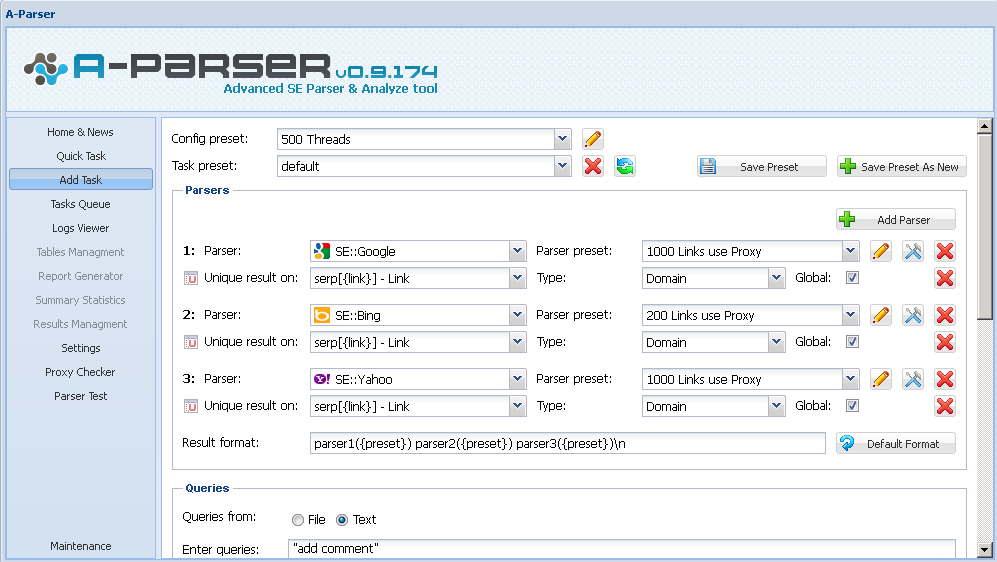
На данном скриншоте показан пример добавления задания на парсинг одновременно трёх поисковых систем - Google, Bing и Yahoo, одновременный уник по домену всех результатов
Ценовая политика
Цена лицензии - 200$, Абонентская плата - 15$ / 3 месяца, первые 3 месяца без абонентской платы.
Лицензия позволяет запускать A-Parser на одном сервере\компьютере. Переносить можно бесплатно, нельзя одновременно на нескольких запускать.
Чтобы купить - зарегистрируйтесь на a-parser.com и стучите в ICQ 777889
Предварительно перед покупкой с удовольствием отвечу на любые ваши вопросы, а так же возможно обсуждение реализации недостающего вам фукнционала. |
|
|
|
|
|
|
![]()
Forbidden
Свой |
Зарегистрирован: 18.02.2009
Сообщений: 66
|
Обратиться по нику
|
| Forbidden |
Ответить с цитатой | | |
|
Версия 0.9.4
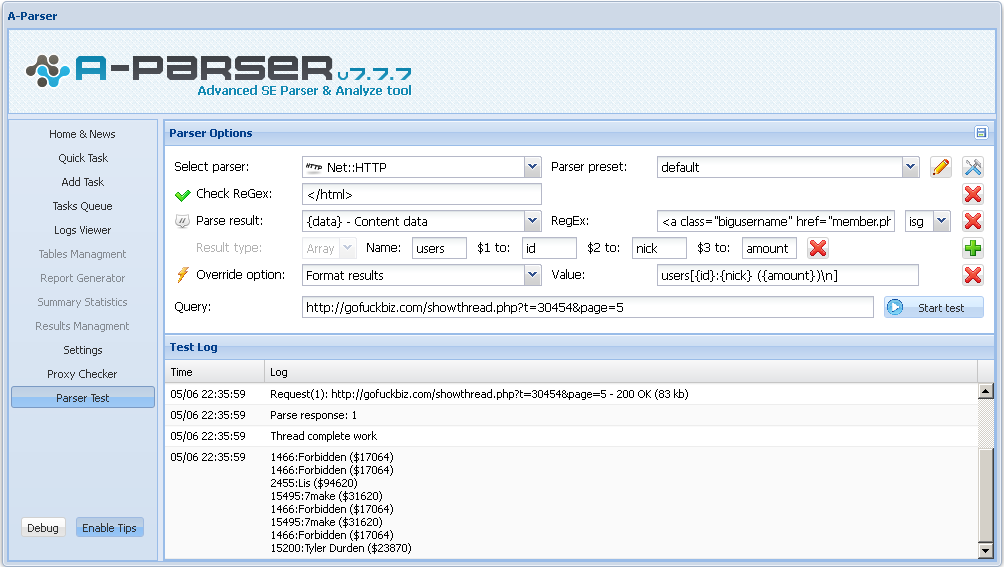
Парсинг результатов регулярными выражениями, Net::HTTP - скачивание страниц, HTML::LinkExtractor - парсинг внутренних и внешних ссылок, SE::Bing::LangDetect - проверка языка сайта, опции в тестовом парсинге, импорт и экспорт пресетов заданий. Теперь можно парсить сторонние ресурсы. Стучите если необходимо составить пресет для специфичного парсинга. Подробнее тут
Пример кастомного парсинга:
Связанные задачи:
| Цитата: |
Улучшение #104: Parser options in Parser Test
Улучшение #132: Check domain language from bing serp
Улучшение #136: Net::HTTP Parser - results: {code} {reason} {headers} {data}
Улучшение #138: Results auto generation with RE match
Улучшение #140: Optional check updates
Улучшение #141: HTML::LinkExtractor - extract internal and external links from url, can follow for internal pages
Улучшение #142: Add import / export configs (base64 json)
Улучшение #144: Implement save task preset from Parser Test
Улучшение #145: Save all parsers options to Task preset
|
|
|
|
|
|
|
|
![]()
Forbidden
Свой |
Зарегистрирован: 18.02.2009
Сообщений: 66
|
Обратиться по нику
|
| Forbidden |
Ответить с цитатой | | |
|
Версия 0.9.16
Новые парсеры
-
 Net::DNS - парсер резолвит домены в IP адреса
Net::DNS - парсер резолвит домены в IP адреса
-
 SE::Google::SafeBrowsing - проверка домена в блеклисте гугла(подпись harm в выдачи)
SE::Google::SafeBrowsing - проверка домена в блеклисте гугла(подпись harm в выдачи)
-
 SE::Google::Position - проверка позиции домена по ключевому слову в гугле
SE::Google::Position - проверка позиции домена по ключевому слову в гугле
Новые возможности
- Подстановка найденных ключевых слов в качестве запросов для парсера SE::Yandex::WordStat, аналогично как сделанно для SE::Google::Suggests
- Поддержка страниц для парсера Net::HTTP, теперь можно делать полноценные парсеры поисковых систем и т.п., пример для aol.com:
Подробнее тут
Версия 0.9.38
15 Исправлений и улучшений, в т.ч. сохраняемый уник при перезагрузки сервера и парсинг всех позиций для SE::Google::Position с выдачей ссылок с серпа!
Связанные задачи:
| Цитата: |
Ошибка #105: A-Parser crash when malformed(ascii 127+) ANSI file as queries used
Ошибка #117: When parse with unique - unique reset after pause/stop and start
Ошибка #120: Sometime parser get 100% cpu usage and closed after ~ 2min
Ошибка #156: Bug when use 2+ active tasks and delete
Ошибка #159: Queries file bug on Win7 x64(unknow encoding)
Ошибка #166: No content when login after failed login
Ошибка #169: waitSlot after pause + start + delete +add new task
Ошибка #174: Query format in Add Task not work without iterator
Ошибка #175: A-Parser crash when bad file name specified as Result file
Ошибка #176: Fix Proxy Checker waiting after load proxies
Ошибка #179: Fix Net::HTTP option Use pages when first page is 0
Улучшение #167: Disable unimplemented task conf in tasks queue
Улучшение #172: Ask before deleting task
Улучшение #177: Parse all positions with SE::Google::Position + output link from serp
Улучшение #181: Add settings "max body size" and "proxy ban time" to all parsers configs
|
|
|
|
|
|
|
|
![]()
Forbidden
Свой |
Зарегистрирован: 18.02.2009
Сообщений: 66
|
Обратиться по нику
|
| Forbidden |
Ответить с цитатой | | |
|
Версия 0.9.57
Новый парсер SE::QIP - парсинг яндекса через search.qip.ru(в т.ч. парсинг до 5000 результатов с одного запроса), выбор времени серпа для гугла и яху, а так же множество исправлений и улучшений!
Подробнее тут
Связанные задачи:
| Цитата: |
Ошибка #164: Unique count not show if use advanced unique
Ошибка #178: Fix 'some error' in queue when connection problems
Ошибка #184: Internal UIDs problem when use pause + start -> server crash
Ошибка #185: Queries format bug when pause\start + iterators
Ошибка #188: Fix SE::Yandex::WordStat
Ошибка #189: Fix interface loading for slow internet connections
Ошибка #190: Fix SE::Yandex content mismatch
Улучшение #158: Serp time selection for Google and Yahoo
Улучшение #191: Add SE::QIP - search.qip.ru parser
|
|
|
|
|
|
|
|
![]()
Forbidden
Свой |
Зарегистрирован: 18.02.2009
Сообщений: 66
|
Обратиться по нику
|
| Forbidden |
Ответить с цитатой | | |
|
Внимание, ценовая политика изменилась с 10.07.2012!
Цена лицензии - 200$, Абонентская плата - 15$ / 3 месяца, первый год без абонентской платы. Условия по абонентской плате так же распространяются и на существующих пользователей!
А так же спец предложение - всем клиентам A-Parser'а бесплатно приватные прокси на 20 потоков на 2 недели!
Всем клиентам кто имеет лицензию на A-Poster - цена всего 150$
А так же A-Parser + A-Poster всего за 300$! |
|
|
|
|
|
|
![]()
Forbidden
Свой |
Зарегистрирован: 18.02.2009
Сообщений: 66
|
Обратиться по нику
|
| Forbidden |
Ответить с цитатой | | |
|
Версия 0.9.69
Новый парсер
 SE::Yandex::TIC - проверка индекса цитирования домена, а так же исправление выдачи Яндекс WordStat и Bing, подробнее тут
SE::Yandex::TIC - проверка индекса цитирования домена, а так же исправление выдачи Яндекс WordStat и Bing, подробнее тут
Связанные задачи:
| Цитата: |
Ошибка #192: Fix Members Area work with https
Ошибка #193: Fix SE::Yandex::WordStat russian html entities
Ошибка #194: Fix SE::Bing for parsing 10+ results and fix links regex
Ошибка #195: Fix UTF-8 for restore unique from file
Улучшение #196: Add Yandex TIC parser - SE::Yandex::TIC
|
|
|
|
|
|
|
|
![]()
Forbidden
Свой |
Зарегистрирован: 18.02.2009
Сообщений: 66
|
Обратиться по нику
|
| Forbidden |
Ответить с цитатой | | |
|
Версия 0.9.166
Большое количество исправлений, доводим парсер до идеального состояния!
А так же плановые фиксы в связи с изменением выдачи для SE::Google и SE::Yandex.
В следующих версиях ожидается новый HTTP движок, который не попал в текущую версию в связи с продолжительным тестированием.
Связанные задачи:
| Цитата: |
Ошибка #163: Some bug in proxycheker
Ошибка #197: Fix not save results after stop\pause + start
Ошибка #198: Fix encoding for non-english for Google, Bing and Yahoo parsers
Ошибка #199: Fix non-english queries parsing with SE::Yahoo
Ошибка #201: Fix Google snippets regex
Ошибка #202: Fix parse custom results with arrays -> server crash
Ошибка #204: Fix SE::Yandex next page regex
Ошибка #210: Fix crash on end of file when file used as iterator
Улучшение #206: Add gzip support for SE::Yandex::TIC
Улучшение #207: UTF-8 auto detect for HTML::LinkExtractor
Улучшение #209: Add gzip support for SE::Google
|
|
|
|
|
|
|
|
![]()
Forbidden
Свой |
Зарегистрирован: 18.02.2009
Сообщений: 66
|
Обратиться по нику
|
| Forbidden |
Ответить с цитатой | | |
|
Версия 0.9.182
Очень важные изменения:
- Новый более быстрый HTTP движок
- Уменьшение потребления памяти
- Общее увеличение производительности за счет внутренних оптимизаций
Улучшения:
- HTML::LinkExtractor: новые результаты {cleananchor} - анкор без html кода, и {nofollow} - определяет есть ли nofollow параметр
- HTML::LinkExtractor: опция Subdomains are internal - считает ссылки со всех сабдоменнов как внутрение
- Макрос {queriesfile} в Results -> File name - подставляет название файла с запросами
Исправления:
- Поправлен парсер SE::Google в связи с изменением формата выдачи
Связанные задачи:
| Цитата: |
Ошибка #211: Fix SE::Google results count regex
Ошибка #212: Fix SE::Google snippets regex
Ошибка #217: Delete tasks with iterator's from completed queue after parser restarting
Улучшение #200: New fast HTTP engine
Улучшение #205: Reduce memory usage by using new http engine
Улучшение #213: Add posibility to use {query} inside arrays in Results format
Улучшение #214: Add {cleananchor} and {nofollow} to results in HTML::LinkExtractor
Улучшение #215: Название исходного файла в results (New macros {queriesfile} in results file name)
Улучшение #219: Add 'Subdomains are internal' option for HTML::LinkExtractor
Улучшение #221: Many internal perfomance improvement and optimizations
|
|
|
|
|
|
|
|
![]()
Forbidden
Свой |
Зарегистрирован: 18.02.2009
Сообщений: 66
|
Обратиться по нику
|
| Forbidden |
Ответить с цитатой | | |
|
Открылась партнерская программа по продаже A-Parser'a - 50$ с каждого приведенного клиента. Подробнее на сайте парсера.
Регистрируйтесь и свяжитесь со мной для активации аккаунта.
Помимо ICQ 777889 теперь со мной можно связаться через jabber/gtalk forbidden2k@gmail.com |
|
|
|
|
|
|
![]()
Forbidden
Свой |
Зарегистрирован: 18.02.2009
Сообщений: 66
|
Обратиться по нику
|
| Forbidden |
Ответить с цитатой | | |
|
Версия 0.9.194
Новые парсеры:
-
 SE::Yandex::Direct - парсер direct.yandex.ru, парсит список всех объявлений(титл, текст, домен) и кол-во объявлений по определенному запросу
SE::Yandex::Direct - парсер direct.yandex.ru, парсит список всех объявлений(титл, текст, домен) и кол-во объявлений по определенному запросу
-
 SE::Google::Images - парсер Google Images, парсит прямые ссылки на картинки, сниппеты, разрешение и размер
SE::Google::Images - парсер Google Images, парсит прямые ссылки на картинки, сниппеты, разрешение и размер
Новые возможности:
- Опция, позволяющая парсить разные задания использую одну базу для уникализации, т.е. теперь можно при появлении новых признаков той же категории допарсить только новые результаты в старую базу
- Возможность залогиниться в 2+ парсера в одном браузере
Всего 12 улучшений и исправлений
Связанные задачи:
| Цитата: |
Ошибка #222: Fix iterator cleanup when set any error
Ошибка #223: Fix work end when string with zero used in queries/subs files
Ошибка #225: Fix server crash when use Unique queries + iterators + pause start
Ошибка #228: Fix max size handling in http engine
Ошибка #232: Fix pages count on active queue tab
Улучшение #161: Add option for check existing results file for unique before task start(implemented with Keep Unique option)
Улучшение #165: Show old results count when server restart
Улучшение #224: New parser SE::Google::Images - parsing full urls to images, with snippets, width, height and size information
Улучшение #226: New parser SE::Yandex::Direct - direct.yandex.ru parser with total ads count and all ads list(domain, title, text)
Улучшение #227: Allow login to 2+ A-Parser's on same ip/domain
Улучшение #230: Check unique level when restore tasks
Улучшение #231: Disable editing default presets
|
|
|
|
|
|
|
|
![]()
Forbidden
Свой |
Зарегистрирован: 18.02.2009
Сообщений: 66
|
Обратиться по нику
|
| Forbidden |
Ответить с цитатой | | |
|
Версия 0.9.200
Новые парсеры:
-
 Rank::Ahrefs - парсер количества беклинков с сервиса ahrefs.com, парсит общее число беклинков, количество ссылающихся страниц, количество уникальных IP-адресов, подсетей класса C и количество уникальных доменов
Rank::Ahrefs - парсер количества беклинков с сервиса ahrefs.com, парсит общее число беклинков, количество ссылающихся страниц, количество уникальных IP-адресов, подсетей класса C и количество уникальных доменов
-
 SE::Bing::Translator - переводчик через сервис www.bing.com/translator/, поддерживает все языки сервиса, включая автоопределение языка оригинала текста
SE::Bing::Translator - переводчик через сервис www.bing.com/translator/, поддерживает все языки сервиса, включая автоопределение языка оригинала текста
-
 Rank::Category - автоматически определяет категорию сайта на английском языке, категории такие же как в dmoz.org, например google.com - Computers/Internet/Searching
Rank::Category - автоматически определяет категорию сайта на английском языке, категории такие же как в dmoz.org, например google.com - Computers/Internet/Searching
Новые возможности:
- Дополнительные опции по сохранению результатов - возможность добавить произвольный текст в начало и конец файла результата, может использоваться к примеру для обозначения названий колонок при формировании результата в csv виде
Связанные задачи:
| Цитата: |
Ошибка #236: Fix active slot counting when server restart
Улучшение #234: Re-enable https with old http engine
Улучшение #235: New parser Rank::Ahrefs - ahrefs.com parser (backlinks/pages/ips/subnets/domains count)
Улучшение #237: Определение тематики сайта
Улучшение #238: Limit queries field length to 8192 characters
Улучшение #239: More options in add task: prepend and append text in results file(e.g. for cols names)
Улучшение #241: SE::Bing::Translator - translator between any 2 languages, with auto-detect
|
|
|
|
|
|
|
|
![]()
Forbidden
Свой |
Зарегистрирован: 18.02.2009
Сообщений: 66
|
Обратиться по нику
|
| Forbidden |
Ответить с цитатой | | |
|
Версия 0.9.209
Новый парсер
 Rank::CMS - определение более 200 видов CMS на основе признаков. Определяет все популярные форумы, блоги, CMS, гестбуки, вики и множество других типов движков.
Rank::CMS - определение более 200 видов CMS на основе признаков. Определяет все популярные форумы, блоги, CMS, гестбуки, вики и множество других типов движков.
Появилась версия с User API, теперь можно интегрировать A-Parser в свои скрипты и программы, более подробно про API описано тут: User API, взаимодействие с другими программами и скриптами
Исправлен парсер
 SE::Yandex
SE::Yandex
Общее повышение стабильности, улучшение интерфейса и другие фиксы.
Связанные задачи:
| Цитата: |
Ошибка #157: Bug when use non-english presets name
Ошибка #229: Need to auto-flush unique file because it may corrupt if process kill
Ошибка #242: Fix server crash after restarting task with iterator error
Ошибка #244: HTML::LinkExtractor fail with relative links starting with dot-shlash
Ошибка #245: Query format fail for subqueries when use iterator + parse to level option
Ошибка #247: Fix utf-8 check for subqueries files
Ошибка #255: Fix SE::Yandex: gzip and next page regex
Улучшение #243: Disable editing all fixed combobox
Улучшение #246: Need to reload presets combobox's when adding/deleting presets
Улучшение #251: New parser Rank::CMS - auto detect CMS type
Улучшение #252: Implement User Api: ping and oneRequest(parser, preset, query)
Улучшение #253: Fast proxy delivery for new threads
|
|
|
|
|
|
|
|
![]()
Forbidden
Свой |
Зарегистрирован: 18.02.2009
Сообщений: 66
|
Обратиться по нику
|
| Forbidden |
Ответить с цитатой | | |
|
Версия 0.9.220
Улучшения
- В парсер
SE::Yandex добавлена возможность выбора домена yandex.ua для парсинга, так же для этого парсера теперь конвертируется количество результатов в число.
- Для парсера
 SE::Google добавлена опция строгого поиска, т.е. если Google говорит что результатов не найдено, но предлагает другие результаты, то парсер не будет их учитывать.
SE::Google добавлена опция строгого поиска, т.е. если Google говорит что результатов не найдено, но предлагает другие результаты, то парсер не будет их учитывать.
- Теперь при экспорте пресета сохраняются все значимые настройки(кроме самих запросов).
Исправления
- В этой версии исправлена ошибка с утечкой сокетов при использовании SOCKS прокси, а так же несколько других ошибок влияющих на общую стабильность парсера.
Связанные задачи:
| Цитата: |
Ошибка #260: Fix SE::Yahoo regex(loop)
Ошибка #262: Fix wrong proxy ban when malformed url used(status == 595)
Ошибка #265: Fix sockets leak when use socks proxies in new http engine(important!)
Ошибка #267: Fix warnings when fast stop parser test
Ошибка #268: Fix handling cookie expire date(for too big date or unparsable date automatic set expire to now + 1 year)
Улучшение #256: Add option for SE::Google for check not found resutls
Улучшение #257: Convert to numeric results count for SE::Yandex
Улучшение #258: Add more options to import/export presets
Улучшение #263: Зоны парсинга Yandex (option Yandex domain allow select yandex.ua)
Улучшение #264: Show warning for too many subrequests
|
|
|
|
|
|
|
|
![]()
Forbidden
Свой |
Зарегистрирован: 18.02.2009
Сообщений: 66
|
Обратиться по нику
|
| Forbidden |
Ответить с цитатой | | |
|
Версия 0.9.233
В этой версии полностью закончена разработка нового сетевого стека:
- Добавлена поддержка SSL/TLS для работы с сокетами
- Новый HTTP движок поддерживает HTTPS, старый движок полностью отключен
В целом теперь возможна работа по любым защищенным SSL/TLS протоколам через любые прокси. Полный отказ от старого движка уменьшил потребление памяти.
Исправлен парсер
SE::Yandex, в парсер
SE::Google::Suggest добавлена возможность выбора регионального домена гугла для парсинга.
Связанные задачи:
| Цитата: |
Ошибка #32: Stopping server bug
Ошибка #271: Fix regex for SE::Yandex(loop)
Улучшение #272: Add posibility to select google regional domain in SE::Google::Suggest
Улучшение #274: New socket-tls engine
Улучшение #275: New http engine now support HTTPS, old module totaly deprecated
|
|
|
|
|
|
|
|
![]()
Forbidden
Свой |
Зарегистрирован: 18.02.2009
Сообщений: 66
|
Обратиться по нику
|
| Forbidden |
Ответить с цитатой | | |
|
Версия 0.9.240
В этой версии несколько улучшений прокси чекера:
- Загрузка проксей из локального файла
- Возможность указать дополнительные регулярные выражения при парсинге проксей с внешних источников
- Сохранение живых проксей в локальный файл для последующего использования в других программах
Подробнее можно прочитать в документации: Все о прокси чекере
В API добавлена возможность парсинга нескольких запросов в многопоточном режиме, а также опция позволяющая возвращать результат выполнения в виде структуры данных, подробнее в документации: User API, взаимодействие с другими программами и скриптами
Парсер
 Net::HTTP теперь автоматически перекодирует содержимое страницы в UTF-8, исходная кодировка вычисляется на основании meta-тега http-equiv и заголовка Content-Type.
Net::HTTP теперь автоматически перекодирует содержимое страницы в UTF-8, исходная кодировка вычисляется на основании meta-тега http-equiv и заголовка Content-Type.
Парсер
Rank::CMS ускорен в ~10 раз, сейчас средняя скорость проверки CMS по всем 277 типам движков составляет около 1500 ссылок в минуту.
Связанные задачи:
| Цитата: |
Улучшение #162: Add posibility to load proxy from file(files/proxy/proxy.txt)
Улучшение #266: добавить возможность добавления регулярок для парсинга проксей(files/proxy/regex.txt)
Улучшение #277: Increase Rank::CMS speed x10
Улучшение #278: First filter result, next make unique
Улучшение #279: move files/proxy_sites.txt to files/proxy/sites.txt
Улучшение #280: Possibility to save alive proxies to file files/proxy/alive.txt(option name 'Save alive proxies to file' in Proxy Checker presets)
Улучшение #281: Now Net::HTTP automaticaly decode any site encoding to utf-8
Улучшение #282: Add bulkRequest to API - allow multithread\multirequest parsing
Улучшение #283: Add rawResults option for API - return raw results structure
|
|
|
|
|
|
|
|
| Новая тема |
Написать ответ |
ГЛАВНАЯ
~ РЕКЛАМА И ОБЪЯВЛЕНИЯ | На страницу 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11 ... 14, 15, 16, 17, 18, 19, 20, 21, 22, 23 След. |
|
|
Партнеры

|


