Это быстрый парсер с уклоном на универсальность, удобность и прозводительность.
На данный момент умеет парсить:
Поисковые системы
Google
Bing
Yahoo
Yandex
Каждый парсер может парсить ссылки, анкоры, сниппеты, количество страниц
Для гугла умеет обходить ограничение в 1000 результатов(скоро и для всех остальных парсеров так же будет), т.е. по одному запросу собирает всю выдачу
Парсеры кейвордов
Сервисы поиска ключевых слов
Yandex WordStat - собирает все кейворды и количество показов до указанной страницы. Так же собирает дополнительные кейворды, показы по главному кейворду и дату обновления статистики.
Подсказки поисковых систем
Подсказки и релейтед кеи Google
Подсказки и релейтед Bing
Подсказки, релейтед и трендовые кеи Yahoo
Подсказки и релейтед Yandex
Для подсказок гугла умеет автоматически собирать все кеи(подстановки до указанного уровня), для всех остальных парсеров такая возможность скоро так же появится
Параметры сайтов и доменов
Google PageRank - PR страниц и доменов
DMOZ - наличие сайта в каталоге DMOZ
Google TrustRank - проверка сайта на траст гугла(дополнительный блок ссылок в выдаче и т.п.)
Whois - дата экспайра домена
Планируется еще много парсеров в ближайшем будущем, все созданно для того чтобы быстро добавлять новые парсеры.
Не было бы никакого A-Parser'а если бы не он не имел все нижеперечисленные преимущества, оставляя остальные парсеры далеко в стороне:
Полностью интерактивный мега-юзабильный веб интерфейс
Быстрое добавление заданий - Quick Task, когда не нужны никакие настройки, а хочется только побыстрому спарсить результаты
Расширенный редактор заданий, позволяет комбинировать несколько парсеров в одном задании, к примеру можно одновременно парсить ссылки со всех парсеров поисковых систем, делать уник по всем результатам прямо в процессе работы и т.д.
Очередь заданий - статистика в реальном времени, выполнение одновременно нескольких заданий и т.д.
Встроенные подсказки для элементов управления позволяют просматривать хелп непосредственно в интерфейсе
Поддержка русского и английского языка
Огромная скорость работы
Поддержка двух самых популярных платформ - Linux и Windows, производительность под Windows фактически не отличается от Linux версии
Открытая разработка, багтрекер, выслушивание всех мнений и их реализация
Первоклассная тех поддержка, знакомая многим по моему старому проекту - A-Poster'у
Данный список можно еще долго продолжать, в ближайшее время все уникальные возможности и подробное их описание появится в Wiki
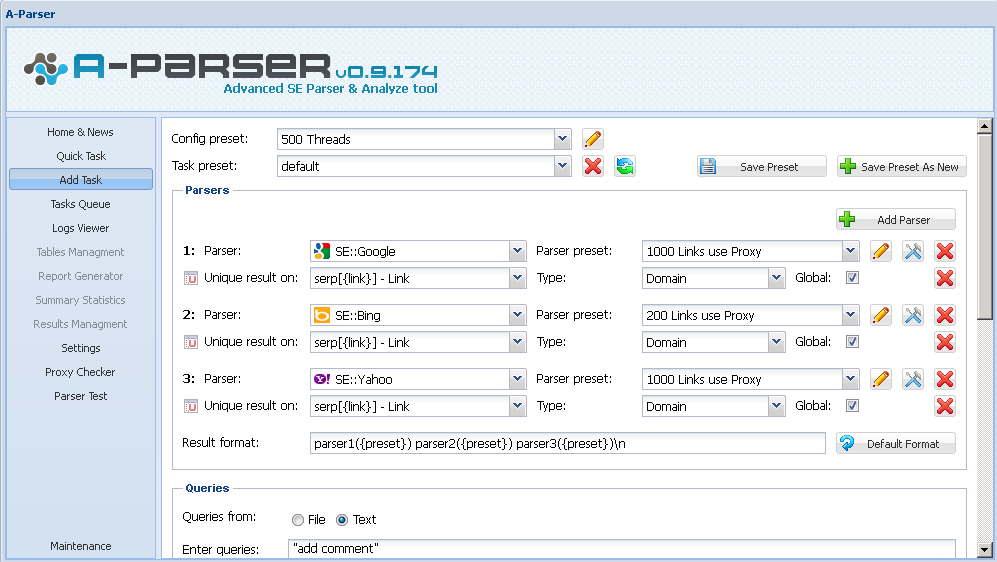
На данном скриншоте показан пример добавления задания на парсинг одновременно трёх поисковых систем - Google, Bing и Yahoo, одновременный уник по домену всех результатов
Ценовая политика
Цена лицензии - 200$, Абонентская плата - 15$ / 3 месяца, первые 3 месяца без абонентской платы.
Лицензия позволяет запускать A-Parser на одном сервере\компьютере. Переносить можно бесплатно, нельзя одновременно на нескольких запускать.
Чтобы купить - зарегистрируйтесь на a-parser.com и стучите в ICQ 777889
Предварительно перед покупкой с удовольствием отвечу на любые ваши вопросы, а так же возможно обсуждение реализации недостающего вам фукнционала.
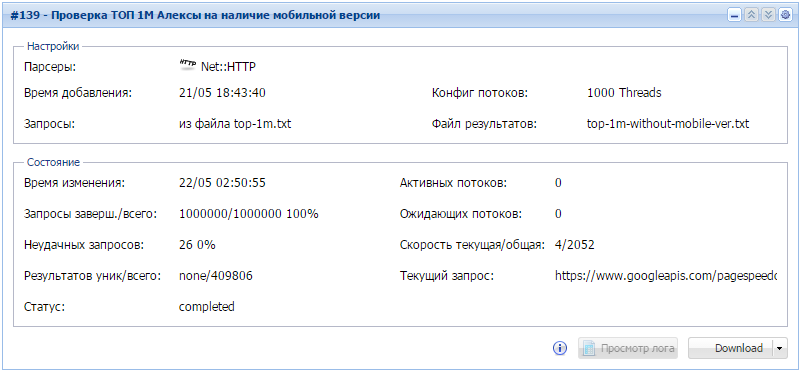
Работаем с большими объемами данных и учимся искать совпадения в raw data.
за 8 часов работы данного задания мы узнали что почти 41% самых посещаемых сайтов не имеют мобильных версий. Кто знает, возможно обзаведясь мобильной версией, они стали бы еще более посещаемыми?
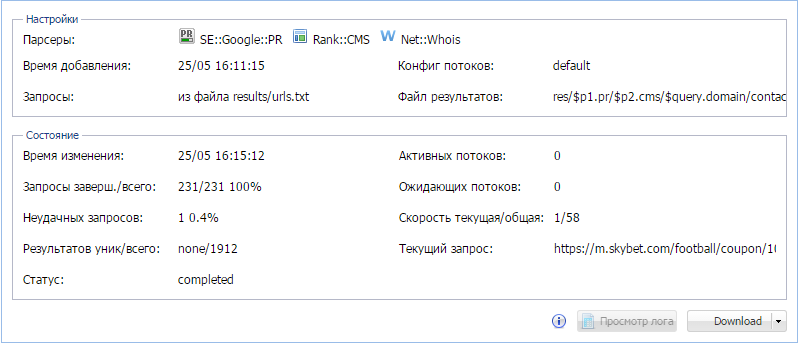
Комплексное задание, выполняемое в 2 этапа, в котором мы учимся работать с несколькими парсерами, регулярными выражениями, а также красиво выводим результаты во многоуровневые каталоги и несколько файлов.
на первом этапе используется 1 парсер, на втором - 3
в конструкторе результатов используется регулярное выражения для извлечения необходимой информации
результаты выводятся в виде вложенных папок и текстовых файлов по следующей схеме:
Пользуемся возможностями шаблонизатора Template Toolkit. Используем циклы и поиск. А также сохраняем разные результаты в разные файлы.
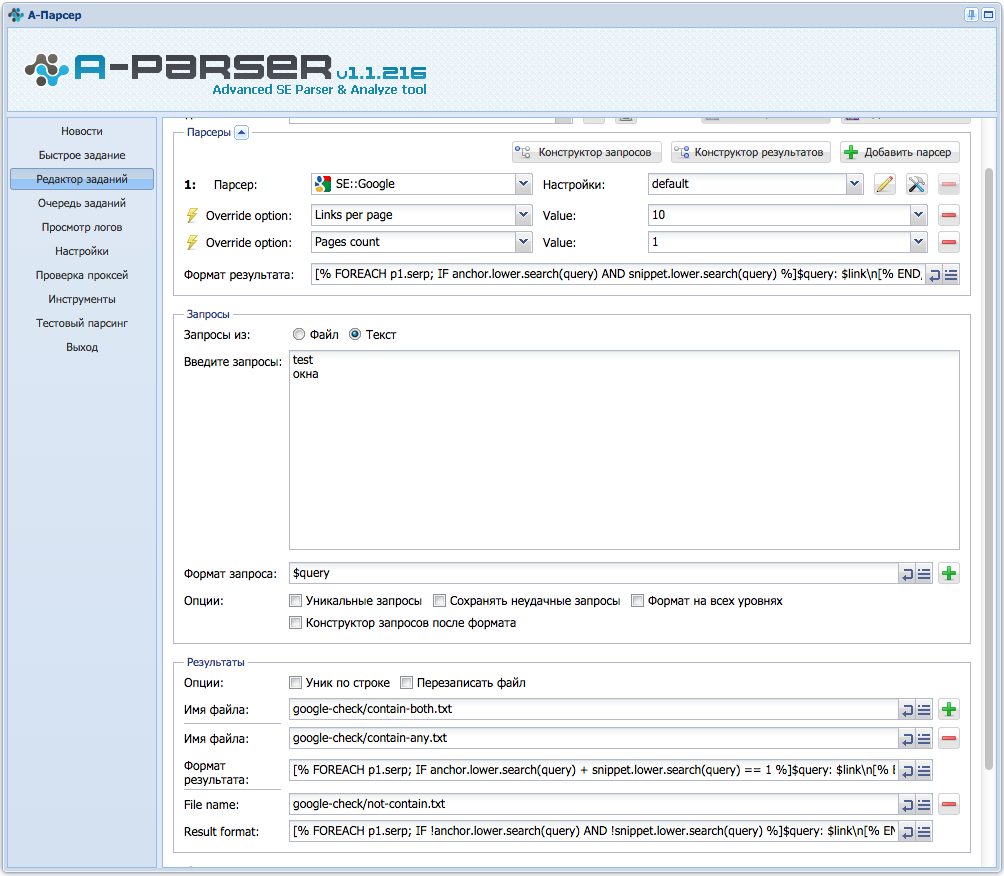
В данном примере осуществляется поиск ключа в анкорах и сниппетах, и в зависимости от результата, сохраняет их в 1 из 3 соответствующих файлов. Все подробности, а также сохранение в 4-ре файла по ссылке выше.
Парсим интернет-магазин и формируем свою HTML-страницу с результатами.
Суть задания заключается в том, чтобы спарсить названия и характеристики товара из интернет-магазина, сохранив привязку к категории и фото товара. Как все это сделать - по ссылке выше.
Сохраняем на жесткий диск различные документы из поисковой выдачи, с определением их типа, а также возможностью формировать уникальное имя файла.
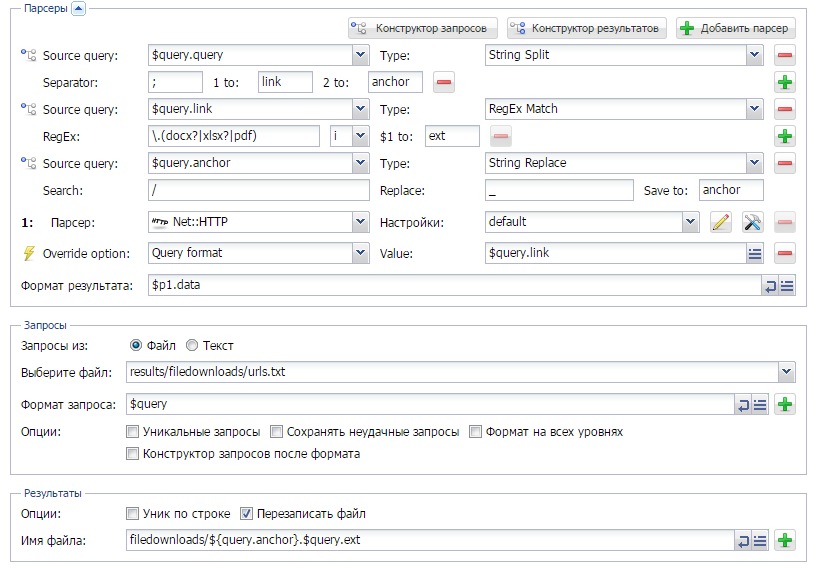
Ну а здесь нам необходимо парсить из выдачи Гугла ссылки на документы формата doc, xls и pdf. Так же необходимо скачивать данные документы, при этом обеспечить уникальность имени файла. Детали - по ссылке выше.
7-й выпуск сборника рецептов. Здесь мы рассмотрим вариант парсинга RSS, будем скачивать картинки в зависимости от их характеристик и научимся фильтровать результат по хедерам.
Парсинг RSS
На сегодняшний день RSS остаются довольно популярным вариантом доставки новостей и контента пользователям. В связи с этим его используют почти на всех сайтах, где бывает более-менее периодическое обновление информации. А для нас это возможность быстро спарсить свежие обновления сайта, не анализируя сам сайт. И один из способов, как это сделать описан по ссылке выше.
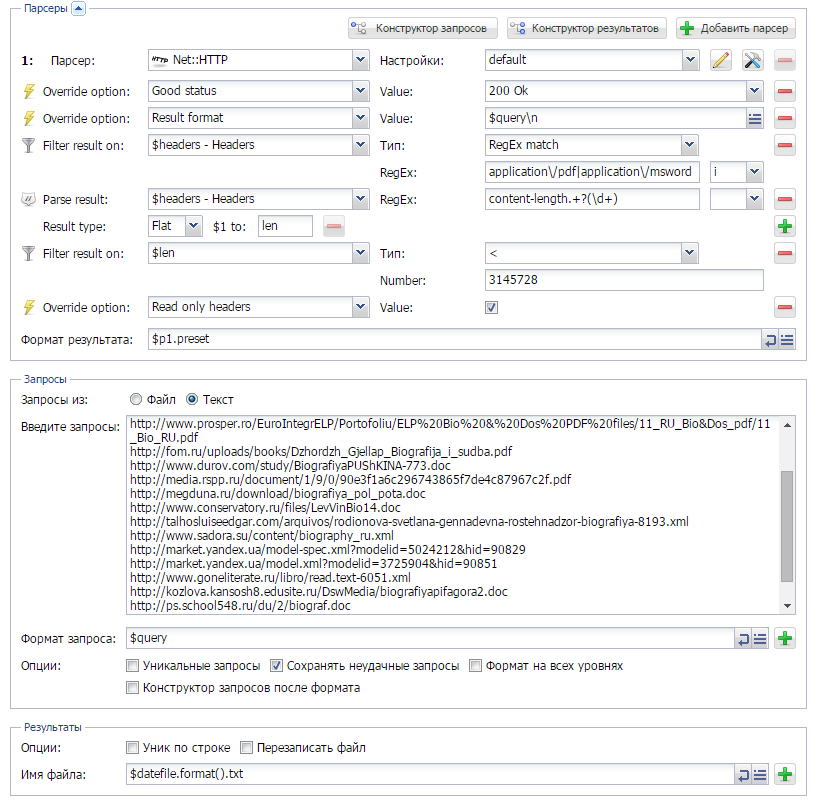
Как фильтровать результат по определенным хедерам?
Как известно, А-парсер предназначен для парсинга, в основном, текстовой информации. Но кроме этого им вполне реально парсить и другие обьекты (файлы, картинки и т.п.). При этом существует возможность фильтровать их по заголовкам ответа сервера. Об этом по ссылке выше.
Скачивание картинок указанного разрешения и размера
Если выше мы фильтровали результат только по хедерам и рассматривали вариант с документами, то в данной статье мы будем скачивать картинки и фильтровать их по размеру и разрешению. Как это сделать - можно увидеть по ссылке выше.
Еще больше различных рецептов в нашем Каталоге примеров!
Предыдущие сборники:
8-й выпуск сборника рецептов. В нем мы будем парсить базу организаций из каталога 2GIS, научимся парсить подсказки из Youtube и напишем кастомный парсер Google translate.
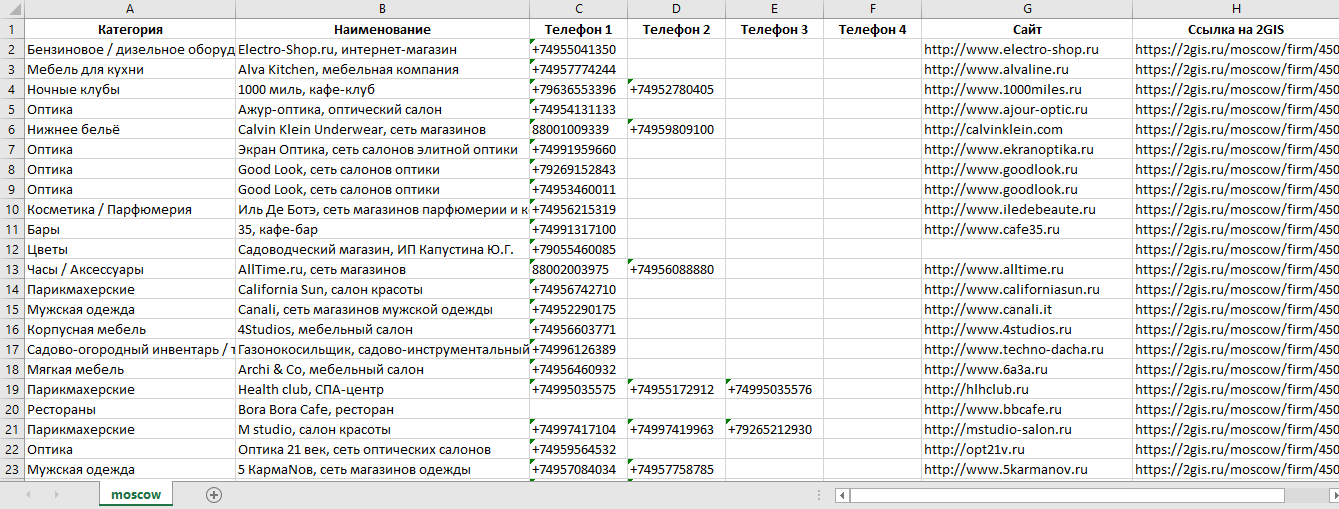
Парсинг 2GIS
2GIS - это довольно большой справочник организаций России (и не только...) с возможностью просмотра их расположения на карте. База содержит более 1580000 организаций в 270 городах России. После парсинга представляет интерес как справочник сайтов, электронных адресов и телефонов организаций.
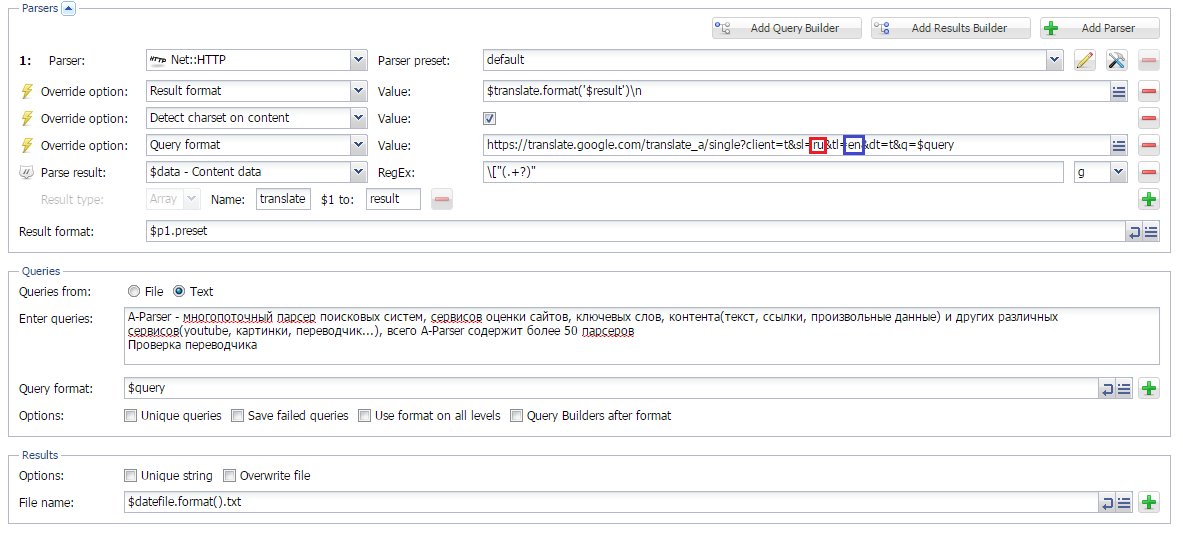
Парсинг Google Translate
В данной статье рассмотрен способ написания кастомного парсера Google translate на основе
Net::HTTP. Также реализована возможность задавать направление перевода. Можно использовать для пакетного перевода больших обьемов текста.
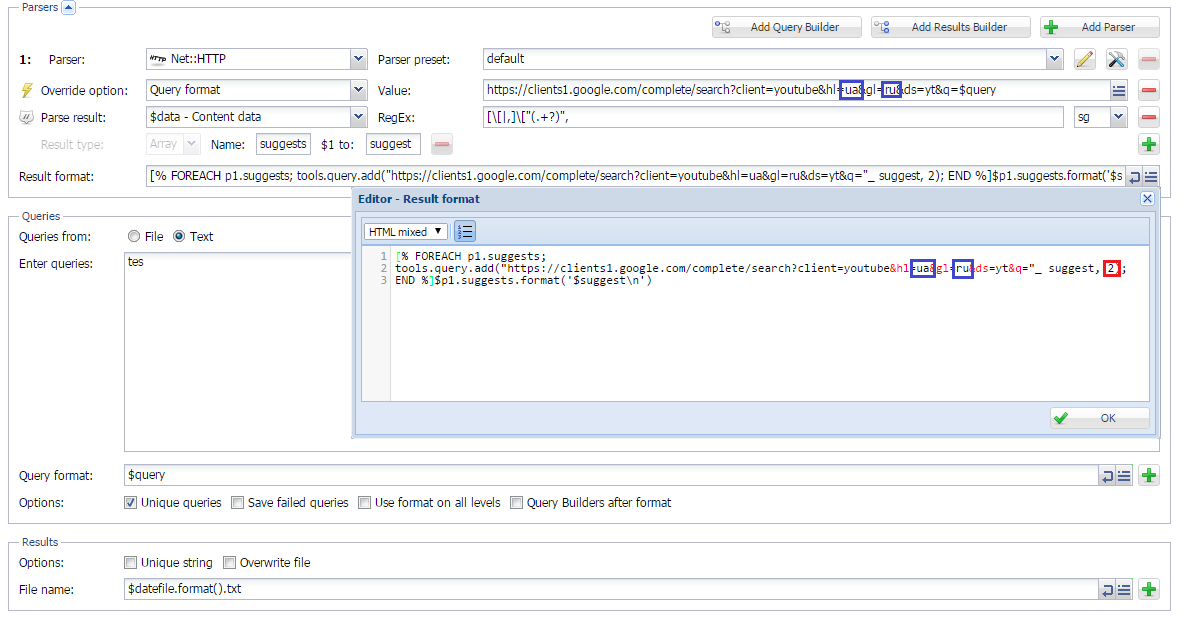
Парсинг подсказок Youtube
Парсинг подсказок поисковых систем - довольно популярный способ поиска ключевых слов. В данной статье также используется
Net::HTTP, с помощью которого создается кастомный парсер подсказок Youtube. Реализована возможность задавать язык и страну, а также использовать уже спаршенные подсказки в качестве новых запросов на нужную глубину.
Еще больше различных рецептов в нашем Каталоге примеров!
Предыдущие сборники:
9-й выпуск Сборника рецептов. В нем мы будем работать с ключевыми словами: проверять их сезонность и искать свободные ниши в рунете, проверяя "полезность" ключевиков.
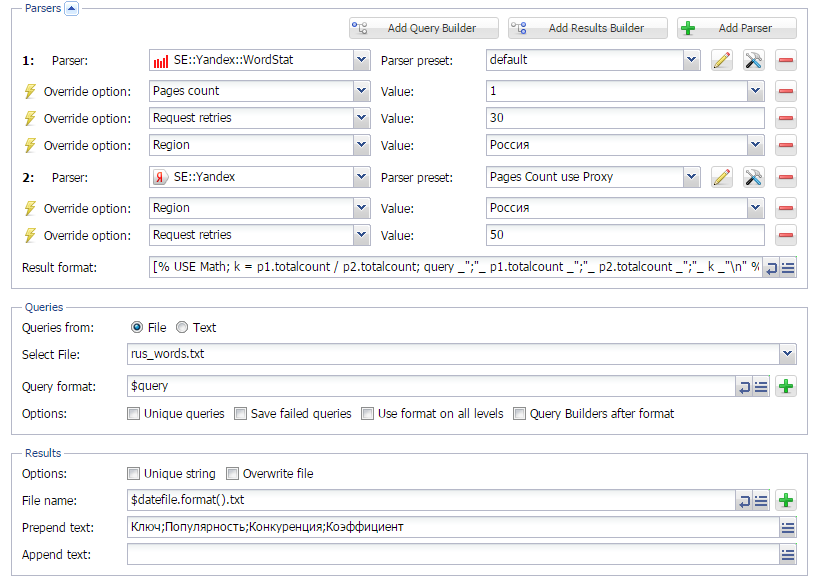
Определение сезонности ключевых слов через Wordstat
Использование нужных ключевых слов в нужное время - один из способов привлечения дополнительного трафика на сайт. Для определения сезонности ключевых слов существует немало различных способов и сервисов. О том, как это делать с помощью А-Парсера - читайте по ссылке выше.
Поиск свободных ниш в RU сегменте интернета
Используя на сайте не только сезонные, а и "полезные" ключевые слова, можно значительно повысить шансы попасть в ТОП10 поисковиков. И если о сезонности мы писали ранее, то о "полезности", а точнее о "незанятости" ключевых слов мы поговорим в данной статье. Полезные или незанятые - это такие КС, которые пользователи часто ищут, но конкуренция по которым не очень высокая. Как их искать - читайте по ссылке выше.
10-й выпуск Сборника рецептов. В нем мы сделаем кастомный парсер поисковика search.disconnect.me и научимся парсить категории из сайтов с сохранением иерархии и путей к ним.
Парсер search.disconnect.me или альтернатива inurl Google
В одном из сообщений на форуме был упомянут довольно интересный сервис search.disconnect.me. Также в последнее время все чаще стали появляться сообщения о проблемах при парсинге Гугла с поисковыми операторами. А так как вышеупомянутый сервис позволяет парсить Гугл, при этом не выдавая каптч и без бана прокси, можно попробовать сделать для него парсер на основе
Net::HTTP. Что из этого получилось - можно посмотреть по ссылке выше.
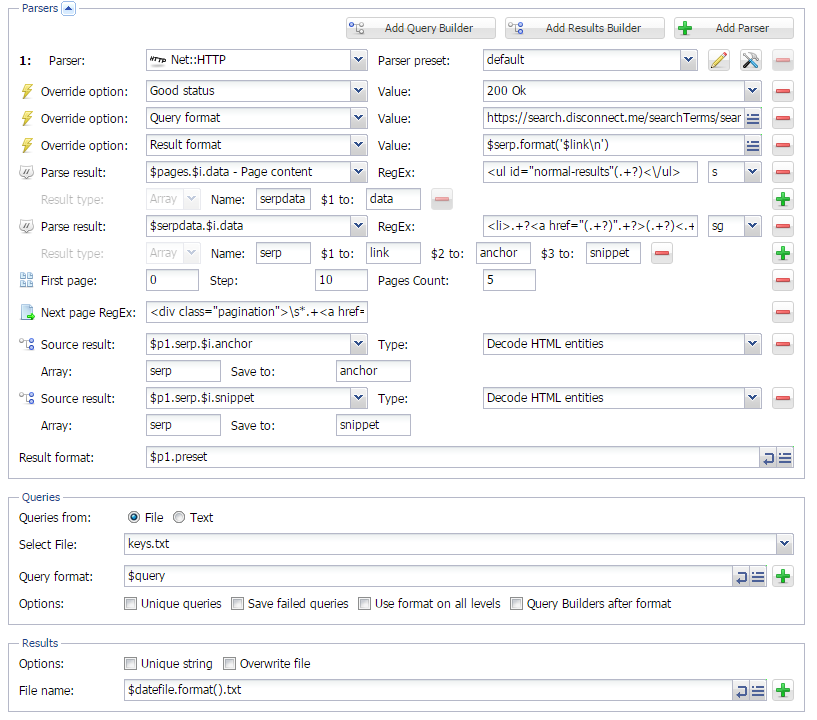
Парсинг дерева категорий с сохранением структуры
В версии 1.1.292 появилась новая опция Query Builders on all levels. С ее помощью можно регулировать, когда применять Конструктор запросов при парсинге "в глубину". И благодаря этой опции стало возможным парсить дерево категорий из сайтов с сохранением структуры. Как это работает - можно посмотреть по ссылке выше.
Добавлен новый Тестировщик заданий, позволяющий тестировать все задание целиком, включая использование нескольких парсеров, конструкторов запросов и результатов. Тестировщик позволяет просматривать результаты по каждому созданному файлу, а также отображает логи выполнения по каждому запросу
Для парсера
Net::Whois добавлена опция Recursive query, которая позволяет получать расширенную версию WHOIS(контактные email адреса и т.п.)
Постоянно пользуюсь парсером! Помогает во многом, имеет гибкую и понятную настройку. В нем имеется множество интсрументов для получения нужных результатов от парсинга контента до индексации сайтов, а так же многое другое!
Добавлен парсер
SE::DisconnectMe - поисковая система от бывших сотрудников Google, можно выбирать один из трех вариантов выдачи: Google, Bing, Yahoo
Теперь при сохранении пресета задания, сохраняется название файла запросов или сам список запросов
При экспорте задания, появилась возможность указать включать или нет запросы в код пресета, а также теперь отображается список настроек парсеров которые будут включены в код
В очереди заданий добавлена возможность свернуть\развернуть одновременно все задания на странице
В очереди заданий для свернутых заданий теперь отображается время выполнения
Увеличена скорость парсинга
SE::Google
Исправления в связи с изменениями в выдачи
В
SE::Google::Images больше не парсится параметр size
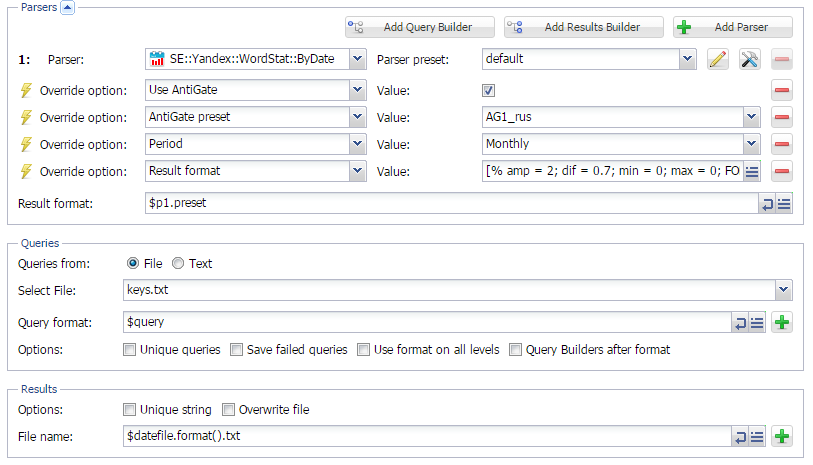
В этой версии проделана большая работа по добавлению поддержки агрегации запросов. Теперь парсер частотности ключевых слов
SE::Yandex::Direct::Frequency может получать данные со скоростью 20000-50000 слов\минуту
Улучшения
Уменьшено потребление памяти при использовании большого числа потоков и\или нескольких парсеров в одном задании
Уменьшено потребление памяти при большой очереди завершенных заданий
В парсере
SE::Yandex::Direct::Frequency добавлена возможность выбрать все регионы или выбрать несколько определенных
В парсере
SE::Yandex::Direct::Frequency добавлена поддержка Яндекс аккаунтов, а так же поддержка AntiGate и парсинг по 500 ключевых слов за один запрос
В парсере
SE::Yandex::Direct::Frequency добавлена возможность выбора периода за последний месяц, за определенный месяц, за квартал или за год
Для Windows и Linux улучшена поддержка юникода в именах файлах, независимо от языка интерфейса ОС
Добавлена возможность просматривать логи только неудачных запросов
В API добавлена возможность указать флаг removeOnComplete при добавлении задания, тем самым задания будут автоматически удалятся после завершения
В просмотре логов теперь можно выделить данные для копирования
В парсере
Net::HTTP добавлен параметр Max cookies count, ограничивающий число Cookie для сохранения
В парсере
Net::HTTP расширен список кодов ответов, а также добавлена возможность указать регулярное выражения для проверки кода ответа
В очереди заданий теперь можно искать необходимые задания по названию, номеру, подстроке в запросах, имени файлов запросов и результатов
В парсере
HTML::LinkExtractor добавлена опция Check next page, позволяющая расширить логику перехода по ссылкам
Добавлена опция Page as new query, которая передает переход на следующую страницу как новый запрос, тем самым позволяя убрать ограничение на количество страниц для перехода
Исправления в связи с изменениями выдачи
В парсере
SE::Yandex исправлен парсинг связанных ключевых слов
В парсере SE::Youtube исправлен парсинг количества видео по запросу
Исправлен парсинг Google Blogs в парсере SE::Google
Вы не можете начинать темы Вы не можете отвечать на сообщения Вы не можете редактировать свои сообщения Вы не можете удалять свои сообщения Вы не можете голосовать в опросах





 Google
Google
 Bing
Bing
 Yahoo
Yahoo
 Yandex
Yandex
 Yandex WordStat - собирает все кейворды и количество показов до указанной страницы. Так же собирает дополнительные кейворды, показы по главному кейворду и дату обновления статистики.
Yandex WordStat - собирает все кейворды и количество показов до указанной страницы. Так же собирает дополнительные кейворды, показы по главному кейворду и дату обновления статистики.

 Google PageRank - PR страниц и доменов
Google PageRank - PR страниц и доменов
 DMOZ - наличие сайта в каталоге DMOZ
DMOZ - наличие сайта в каталоге DMOZ
 Google TrustRank - проверка сайта на траст гугла(дополнительный блок ссылок в выдаче и т.п.)
Google TrustRank - проверка сайта на траст гугла(дополнительный блок ссылок в выдаче и т.п.)
 Whois - дата экспайра домена
Whois - дата экспайра домена

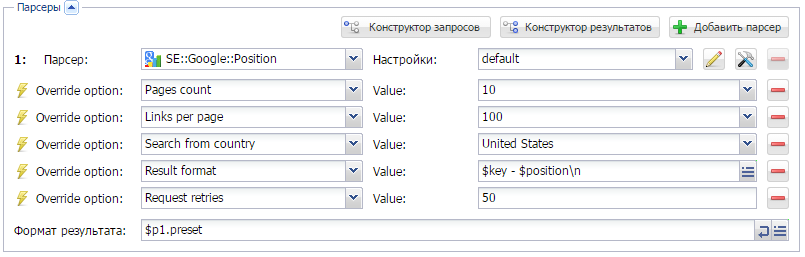
 SE::Google::Position и проверяем на каком месте в поисковой выдачи находится ключевое слово.
SE::Google::Position и проверяем на каком месте в поисковой выдачи находится ключевое слово.



 Net::HTTP. Также реализована возможность задавать направление перевода. Можно использовать для пакетного перевода больших обьемов текста.
Net::HTTP. Также реализована возможность задавать направление перевода. Можно использовать для пакетного перевода больших обьемов текста.

 SE::Yandex::WordStat
SE::Yandex::WordStat
 SE::Yandex
SE::Yandex
 SE::Google::Images
SE::Google::Images
 SE::Bing
SE::Bing
 SE::Yahoo::Suggest
SE::Yahoo::Suggest
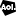 SE::AOL
SE::AOL
 SE::Yandex::TIC - ресурсы у которых тИЦ был неопределен отображались как тИЦ = 0, исправлено на тИЦ = -1
SE::Yandex::TIC - ресурсы у которых тИЦ был неопределен отображались как тИЦ = 0, исправлено на тИЦ = -1
 Net::Whois добавлена опция
Net::Whois добавлена опция 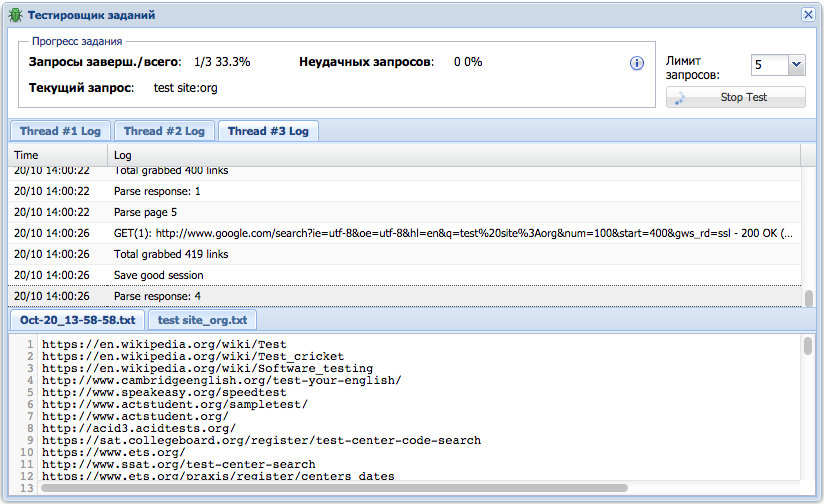
 SE::Google
SE::Google
 SE::Yandex::Register
SE::Yandex::Register
 SE::Google::Suggest
SE::Google::Suggest
 SE::DisconnectMe - поисковая система от бывших сотрудников Google, можно выбирать один из трех вариантов выдачи: Google, Bing, Yahoo
SE::DisconnectMe - поисковая система от бывших сотрудников Google, можно выбирать один из трех вариантов выдачи: Google, Bing, Yahoo
 SE::Google::TrustCheck,
SE::Google::TrustCheck,
 SE::Google::Compromised,
SE::Google::Compromised,
 SE::Ask,
SE::Ask,
 SE::Dogpile,
SE::Dogpile,

 SE::Yandex::Direct::Frequency может получать данные со скоростью
SE::Yandex::Direct::Frequency может получать данные со скоростью  HTML::LinkExtractor добавлена опция Check next page, позволяющая расширить логику перехода по ссылкам
HTML::LinkExtractor добавлена опция Check next page, позволяющая расширить логику перехода по ссылкам
 SEO::ping
SEO::ping