|
|
|
|
![]()
Iceberg
V.I.P. |
Зарегистрирован: 17.03.2010
Сообщений: 12043
|
Обратиться по нику
|
| Iceberg |
Ответить с цитатой | | |
|
Загрузка данных «ВКонтакте»
Для загрузки данных из рекламного кабинета «ВКонтакте» мы будем использовать R-библиотеку rvkstat.
Примечание: до ноября API «ВКонтакте» не выгружал клики по промопостам. С начала ноября API «ВКонтакте» должен корректно работать для новых объявлений.
1. Установите актуальную версию языка R и RStudio. Инсталлируйте пакеты devtools, rvkstat, bigrquery c помощью функций install.packages, install_github.
install.packages("devtools")
install.packages("bigrquery")
install_github('selesnow/rvkstat')
2. Для работы с API «ВКонтакте» вам необходимо создать приложение. Как это сделать, описано в справке библиотеки.
3. С помощью функции vkAuth получаем токен. В аргументах функции необходимо указать свой идентификатор и секрет приложения. После этого откроется страница в браузере с кодом для получения токена, код необходимо скопировать и ввести в консоль.
Для дальнейшей работы полученный токен необходимо указывать при каждом обращении к API.
library(rvkstat)
token <- vkAuth(app_id=11111111, app_secret="xxxxxxxxxxxxxx")
4. Далее получаем список рекламных кабинетов:
vk_accounts <- vkGetAdAccounts(token$access_token)
5. Затем получаем список клиентов. Если у вас личный кабинет, а не кабинет агентства, то этот шаг нужно пропустить.
vk_clients <- vkGetAdClients(account_id=11111111, access_token = token$access_token)
6. Получаем список рекламных кампаний. Для кабинета агентства используем такую функцию:
vk_campaigns <- vkGetAdCampaigns(account_id=11111111, client_id=11111111, access_token = token$access_token)
Если у вас личный кабинет, а не кабинет агентства, то из функции необходимо убрать аргумент client_id:
vk_campaigns <- vkGetAdCampaigns(account_id=11111111, access_token = token$access_token)
7. Получаем статистику по кампаниям c разбивкой по дням.
vk_stat_by_campaign <- vkGetAdStatistics(account_id=11111111,
ids_type="campaign",
ids=vk_campaigns$id,
period="day",
date_from="2017-12-01",
date_to=Sys.Date()-1,
access_token=token$access_token)
Разберем подробнее поля в запросе:
ids_type — тип запрашиваемых объектов, которые перечислены в параметре ids, допустимые значения — ad, campaign, client, office;
ids — идентификаторы запрашиваемых объектов через запятую. Так как у нас есть столбец с id всех кампаний в датафрейме vk_campaigns, то сошлемся на него;
period — группировка данных по датам, допустимые значения — day, month, overall;
date_from — начальная дата выводимой статистики;
date_to — конечная дата выводимой статистики.
Для дат используется разный формат в зависимости от параметра period:
day: YYYY-MM-DD, пример: 2017-12-15;
month: YYYY-MM, пример: 2017-12;
overall: 0.
8. В результате вы получите датафрейм с данными по показам, кликам, расходам, подпискам и другим показателям. Теперь необходимо записать его в Google BigQuery. Для этого воспользуемя функцией insert_upload_job из библиотеки bigrquery.
library(bigrquery)
insert_upload_job("bigquery_project_id", "temp_reports", "vk", vk_stat_by_campaign, "bigquery_project_id", create_disposition = "CREATE_IF_NEEDED", write_disposition = "WRITE_TRUNCATE")
Здесь нужно заменить:
bigquery_project_id — идентификатор проекта в BigQuery;
temp_reports — dataset в BigQuery;
vk — название таблицы для записи данных в BigQuery.
В таблице со статистикой есть идентификаторы кампаний, но нет названий. Чтобы дополнить полученную статистику названиями кампаний, запишем в BigQuery полученный ранее датафрейм со списком рекламных кампаний.
insert_upload_job("bigquery_project_id", "temp_reports", "vk_campaign_list", vk_campaigns, "bigquery_project_id", create_disposition = "CREATE_IF_NEEDED", write_disposition = "WRITE_TRUNCATE")
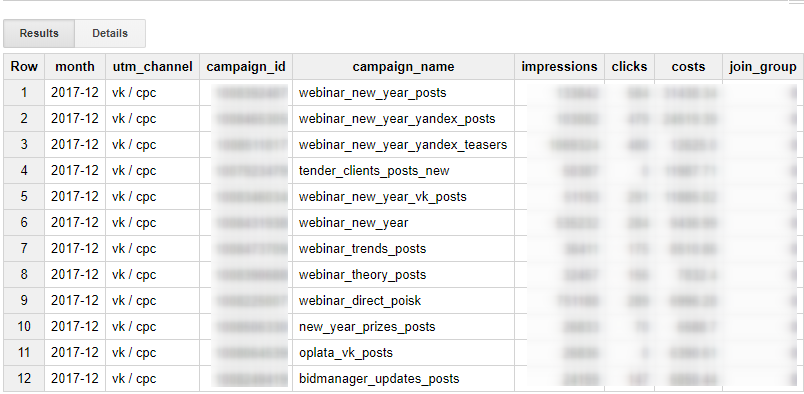
Пример готового SQL-запроса — объединим две таблицы и агрегируем данные по месяцам:
// расходы по кампаниям ВКонтакте
SELECT
LEFT(c.day,7) AS month,
'vk / cpc' AS utm_channel,
c.id AS campaign_id,
n.name AS campaign_name,
SUM(c.impressions) AS impressions,
SUM(c.clicks) AS clicks,
ROUND(SUM(c.spent),2) AS costs,
IFNULL(SUM (c.join_rate),0) AS join_group
FROM temp_reports.vk AS c
LEFT JOIN temp_reports.vk_campaigns_list AS n ON c.id=n.id
GROUP BY month, campaign_id, campaign_name
ORDER BY month DESC, costs DESC
Загрузка данных Facebook
Разберем автоматическую загрузку данных через сервис Owox BI Pipeline Facebook Ads -> Google BigQuery.
Для настройки импорта Facebook Ads -> Google BigQuery нужен действующий поток Facebook -> Google Analytics.
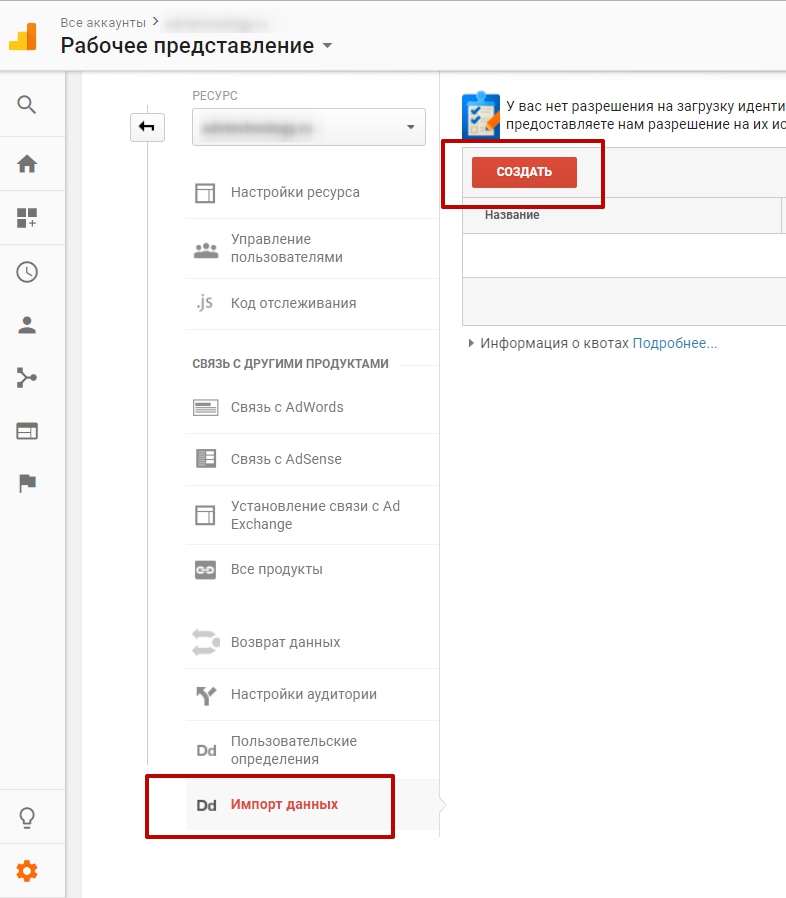
1. Для настройки потока Facebook -> Google Analytics сначала необходимо создать модель данных в Google Analytics, в которую будут импортироваться расходы. Зайдите на вкладку «Администратор», выберите «Импорт данных», нажмите кнопку «Создать».
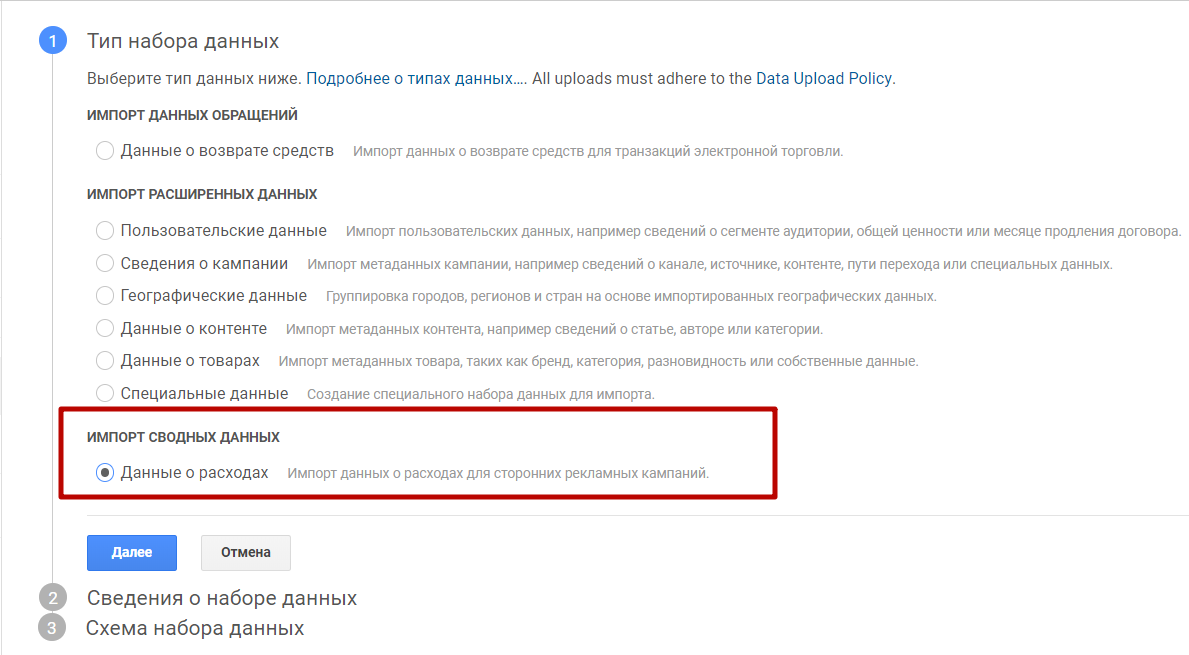
2. Необходимо выбрать тип набора данных. Выберите пункт «Данные о расходах».
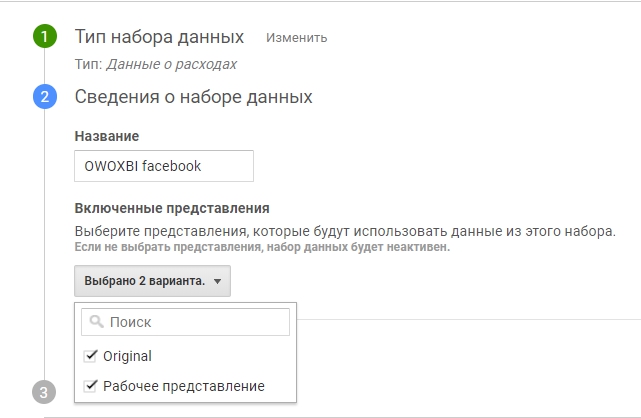
3. Далее задайте название для набора данных и выберите представления, которые будут использовать данные из этого набора.
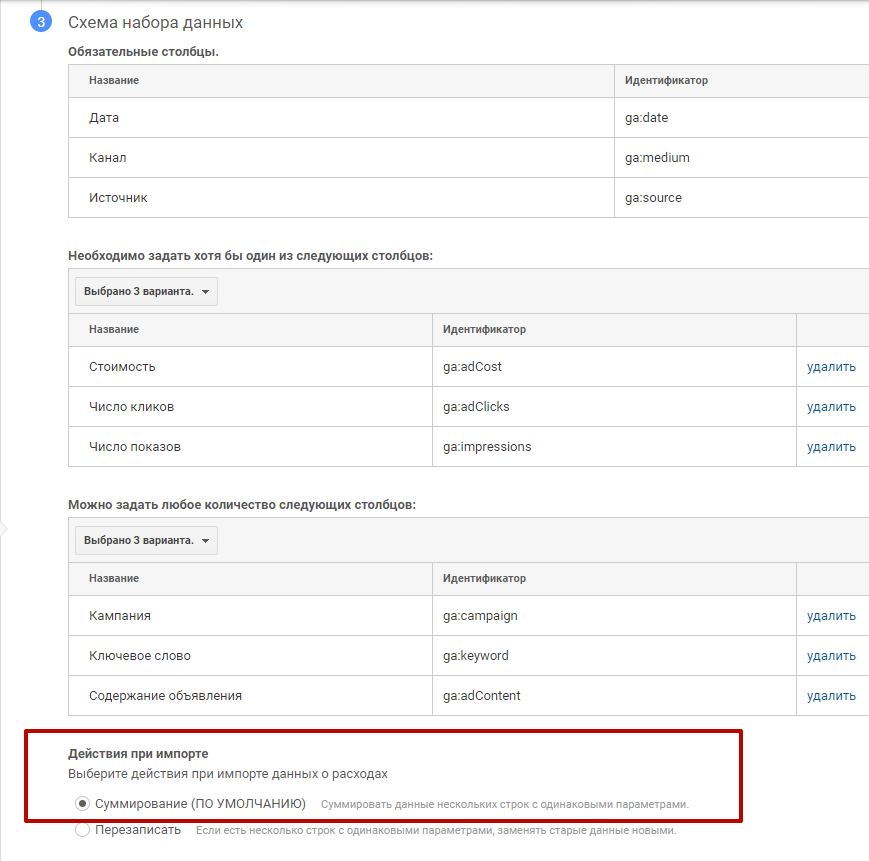
4. Следующий шаг — задайте схему набора данных. К обязательным столбцам (дата, канал, источник) добавьте следующие столбцы: кампания, ключевое слово, содержание объявления. Выберите показатели для импорта: стоимость, число кликов, число показов. Действие при импорте — «Суммирование», после этого нажмите «Сохранить».
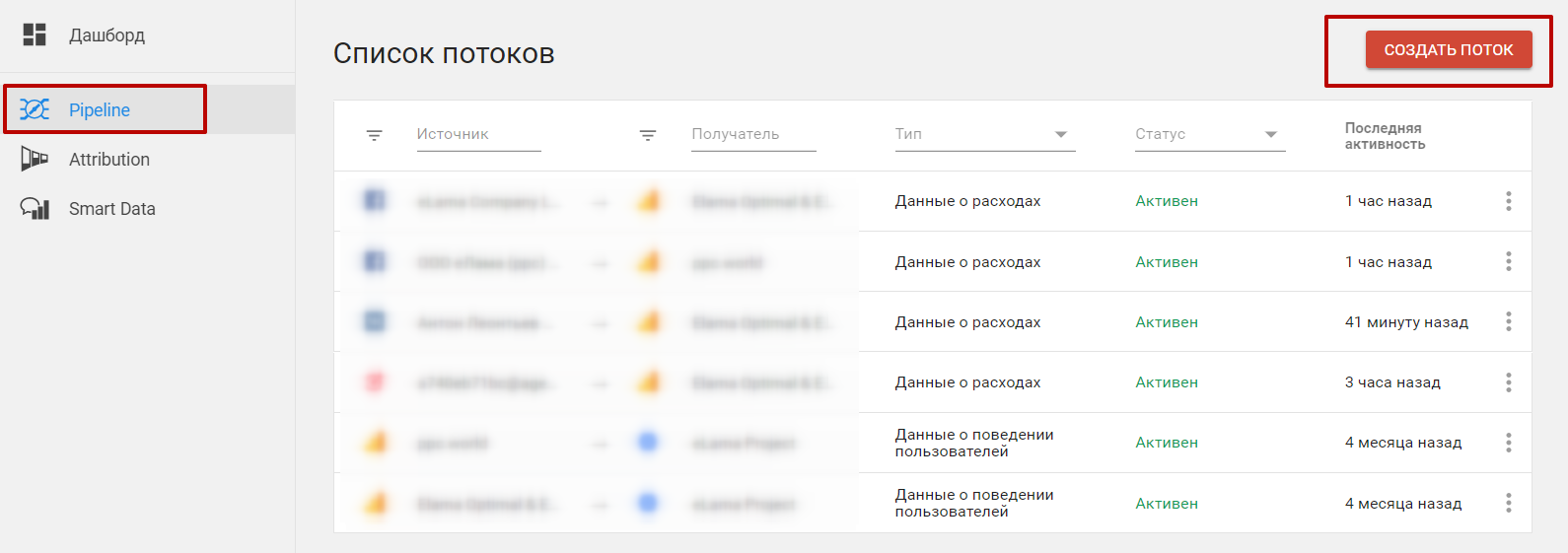
5. Далее настройте поток Facebook -> Google Analytics в кабинете Owox. Перейдите на вкладку Pipeline и нажмите «Создать поток».
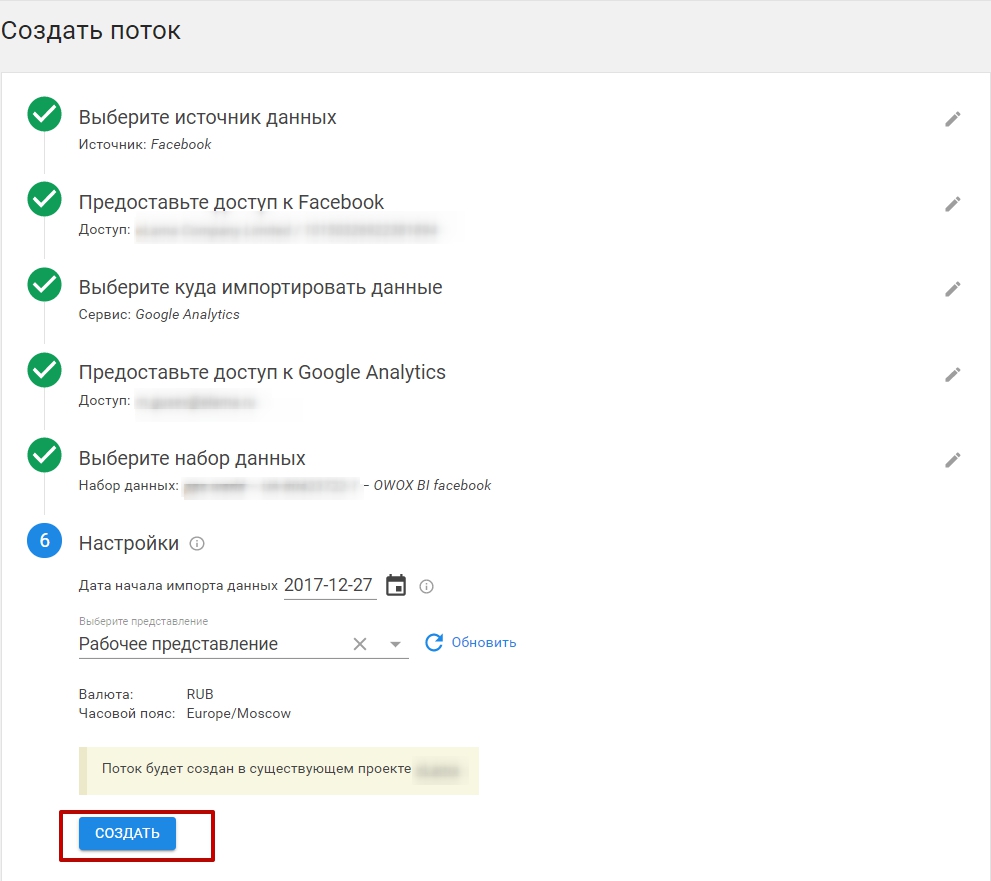
6. Предоставьте доступ к вашим аккаунтам в Facebook и Google Analytics. Далее выберите ресурс Google Analytics и схему данных, которую вы создали. Укажите дату начала импорта данных (историческая загрузка данных возможна, но есть ограничения) и выберите представление. После чего нажмите «Создать».
7. Поток Facebook -> Google Analytics настроен, и в скором времени начнется импорт данных в Google Analytics. Теперь необходимо настроить импорт в Google BigQuery.
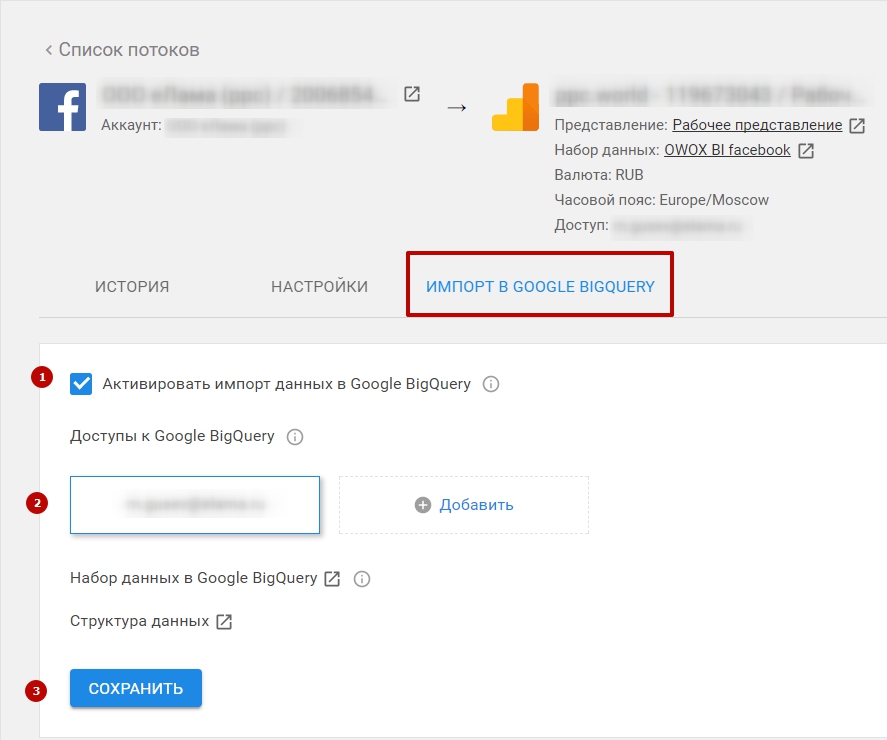
8. Зайдите в поток и перейдите на вкладку «Импорт в Google BigQuery». Активируйте импорт с помощью чекбокса, выберите аккаунт для доступа, нажмите «Сохранить».
9. После этого в BigQuery появится датасет под названием owox-bi-pipeline. Первые данные соберутся в течении суток, а в последствии будут дополняться каждый день. Схему передаваемых данных можно посмотреть в справке Owox.
Пример SQL-запроса для работы с данным датасетом:
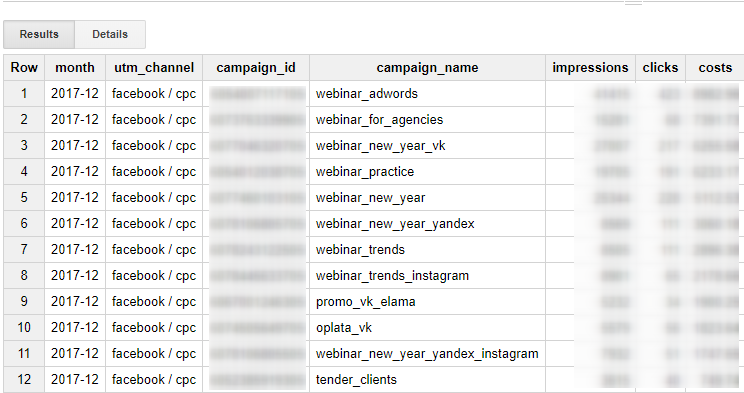
// расходы по кампаниям Facebook
SELECT
LEFT(STRING(insights.data.date_start),7) AS month,
'facebook / cpc' AS utm_channel,
campaign.id AS campaign_id,
campaign.name AS campaign_name,
SUM(insights.data.impressions) AS impressions,
SUM(insights.data.inline_link_clicks) AS clicks,
ROUND(SUM(insights.data.spend),2) AS costs,
FROM
TABLE_DATE_RANGE ([owox-bi-pipeline:54abf072312482b24edfd880c1622a89.facebook_ads_insights_], TIMESTAMP ('2017-12-01'), DATE_ADD(CURRENT_TIMESTAMP(), -1, "DAY"))
WHERE
insights.data.inline_link_clicks IS NOT NULL AND insights.data.spend IS NOT NULL AND insights.data.impressions IS NOT NULL
GROUP BY month, campaign_id, campaign_name
ORDER BY month DESC, costs DESC
|
|
|
|
|
|
|
![]()
TREVERS
V.I.P. |
Зарегистрирован: 20.06.2011
Сообщений: 9820
|
Обратиться по нику
|
| TREVERS |
Ответить с цитатой | | |
|
Iceberg, статья отличная, но с поправкой что она полезна для тех кто под РУ-нет, то есть люто работает с ВК,
а вот кто под бурж им гораздо будет интереснее такое же но под FB увидеть  |
|
|
|
|
|
|
![]()
Iceberg
V.I.P. |
Зарегистрирован: 17.03.2010
Сообщений: 12043
|
Обратиться по нику
|
|
|
|
|
|
|
Партнеры

|



")
